Blog
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

.png)

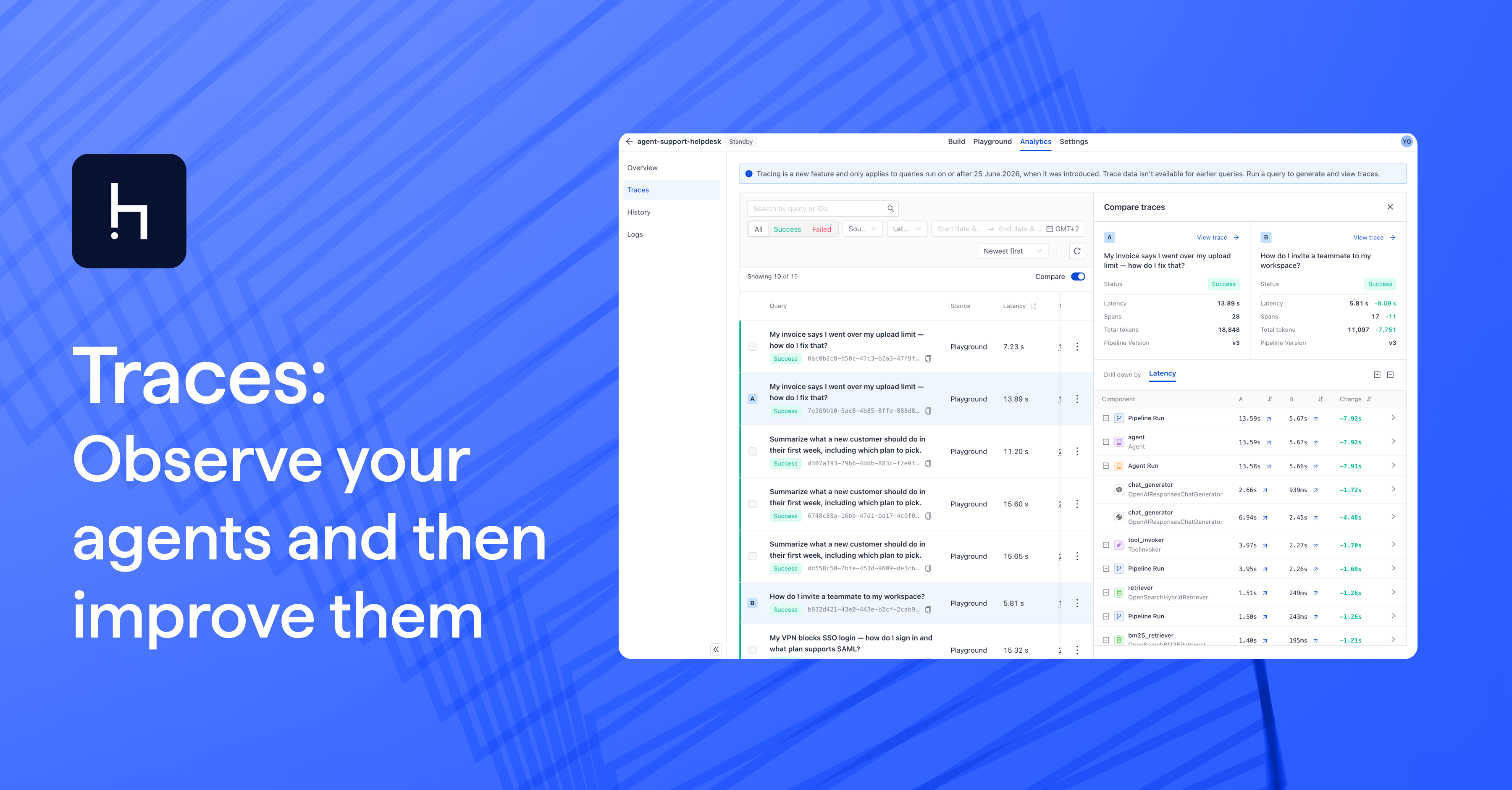
Harness Engineering: How to Build Reliable AI Agents by Engineering the System, Not the Model
Agent reliability doesn't come from picking the right model, it comes from engineering the system around it. Learn what harness engineering is, how to classify and fix agent failures, and how to build production-grade agent harnesses with Haystack.