TLDR
Key Metrics:
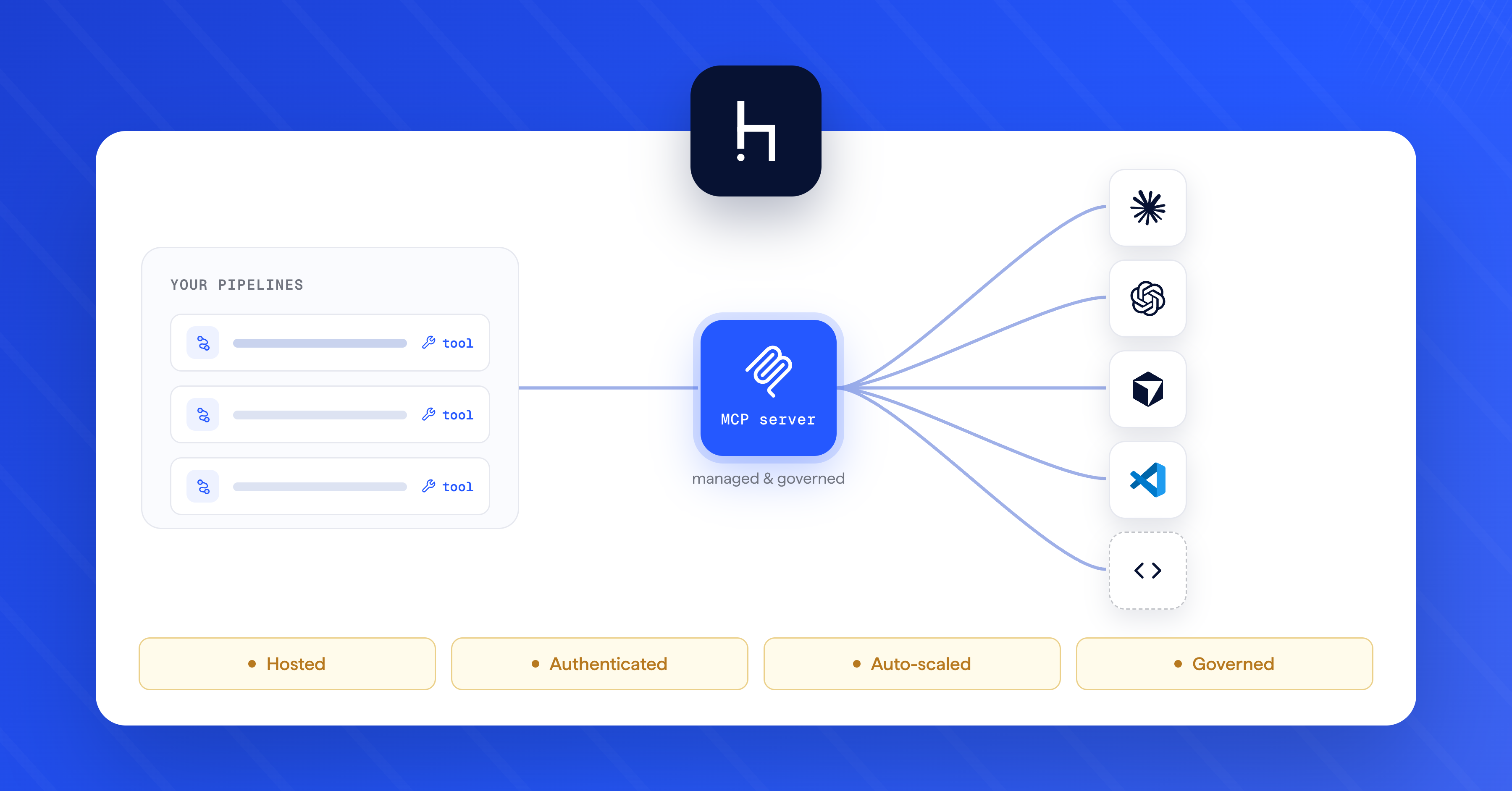
Evaluation is an essential part of every NLP project. It lets you quantify the system’s overall performance, detect any deterioration over time, and compare it to competing configurations. Evaluating your question answering (QA) and document search pipelines in Haystack is now easier than ever. Here’s what’s new:
- There’s no more need for special evaluation nodes. You can now simply run your QA pipeline in evaluation mode by calling it with eval().
- The eval() method call returns an EvaluationResult object. For each node that is being evaluated, the object contains a pandas dataframe with the node’s evaluation results.
- The EvaluationResult object contains a method calculate_metrics(). It generates an overview of all the relevant metrics for the entire pipeline.
Recap: Why evaluation is necessary
A natural language processing system is typically realized as a pipeline that consists of various nodes. The nodes are modular components, each of which takes care of a specific task. A question answering Pipeline usually contains a Retriever and a Reader node.

Once you’ve gotten your QA pipeline to run, the most pressing question that you and others will ask is: “How well is this system doing?” A system’s performance is usually made up of two factors: latency, that is the speed with which it processes requests, and the quality of its predictions. In this blog post, we’ll mainly be looking at prediction quality.
Modern NLP projects are typically not linear, but consist of multiple iterations. Whenever your system doesn’t perform as well as you would like it to — whether in terms of speed or prediction quality — there are many different ways to improve it. You could adjust the hyperparameters, fine-tune the model with newly annotated training data, or even perform model distillation. After completing any of these steps, you’ll need to re-evaluate your system to see whether it actually improved.
In addition to giving you a sense of how well your system is doing — in general and in comparison to other systems — evaluation can also help you identify underperforming components in your pipeline. For example, you can investigate the Retriever’s and the Reader’s performance separately.
How does evaluation work?
In supervised machine learning, a model is trained on labeled data that should mirror the final use case as accurately as possible. To evaluate such a system, you need to set a portion of the data aside before training. This “eval dataset” allows you to later test your trained system’s prediction quality on data it hasn’t seen before. You can then use a set of metrics to quantify how well your system’s predictions compare to the real, “gold” labels.
SQuAD
For question answering systems, training and evaluation data typically comes in the SQuAD (Stanford Question Answering Dataset) format. Its authors describe SQuAD as a “reading comprehension benchmark,” because it is designed to assess how well an extractive QA system can understand a text and answer questions about it.
A SQuAD-like dataset is typically made up of questions and answers based on content from freely accessible text collections like Wikipedia. Crowdworkers read a text passage, come up with possible questions and select an appropriate answer span from the text. To allow for variability in the answers, a question can be paired with up to five answers, chosen by different workers. These answers are not necessarily all different, but can overlap or even be completely identical. To get a better idea, have a look at this visualization of an annotated text passage in SQuAD 2.0.
How to Evaluate a QA Pipeline in Haystack
Previously, if you wanted to evaluate a question answering pipeline in Haystack, you had to add specific evaluation nodes to your pipeline. That is no longer necessary, as you can now directly run eval() on an existing pipeline, and receive an evaluation summary of both the retriever’s and the reader’s performance. The new method isn’t just faster and easier to use, it also ensures consistency of your pipelines across the different stages of the implementation process. Let’s see how that looks in practice.
We’ll work with a small subset of the Natural Questions dataset by Google Research. We converted the original dataset to the SQuAD format, so that every entry contains a question, a context passage, and multiple (potentially identical or overlapping) answers. For the full example code, have a look at our evaluation tutorial, which can be run as a notebook in Colab.
Obtaining the data
The subset can be downloaded from our S3 bucket on AWS:
from haystack.utils import fetch_archive_from_http
doc_dir = "../data/nq"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/nq_dev_subset_v2.json.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
The last function, fetch_archive_from_http(), stores the data in the folder doc_dir in the Colab session’s temporary storage.
Setting up the document store and preprocessor
To connect our QA pipeline, we need to store the data in a database. We’ll be using Elasticsearch for that.
from haystack.document_stores import ElasticsearchDocumentStore
document_store = ElasticsearchDocumentStore(
host="localhost",
username="",
password="",
index=doc_index,
label_index=label_index,
embedding_field="emb",
embedding_dim=768,
excluded_meta_data=["emb"],
)
We’ll also have to define a preprocessor, which splits the data into passages. Here, we define a length of 200 words per passage.
from haystack.nodes import PreProcessor
preprocessor = PreProcessor(
split_length=200,
split_overlap=0,
split_respect_sentence_boundary=False,
clean_empty_lines=False,
clean_whitespace=False,
)
Adding the data to the document store
The following steps serve to make sure that our database doesn’t contain any duplicates:
doc_index = "tutorial5_docs"
label_index = "tutorial5_labels"
document_store.delete_documents(index=doc_index)
document_store.delete_documents(index=label_index)
Now it’s time to feed our documents and labels to the document store. The following method call converts the data contained in our JSON file into Haystack document and label objects. It can be used for any evaluation dataset, provided that it comes in SQuAD format.
document_store.add_eval_data(
filename="../data/nq/nq_dev_subset_v2.json", doc_index=doc_index, label_index=label_index, preprocessor=preprocessor
)
Implementing the extractive QA pipeline
Now that our database contains the evaluation data, it’s time to set up our retriever and reader nodes. We import the sparse BM25Retriever and connect it to our document store:
from haystack.nodes import BM25Retriever
retriever = BM25Retriever(document_store=document_store)
Next, we import and initialize the reader:
from haystack.nodes import FARMReader
reader = FARMReader("deepset/roberta-base-squad2", return_no_answer=True)
Now we’ll set up the pipeline.
from haystack.pipelines import ExtractiveQAPipeline
pipeline = ExtractiveQAPipeline(reader=reader, retriever=retriever)
Tada! Our pipeline is ready.
Running the pipeline
To run the pipeline in evaluation mode, we need to get the real “gold” labels for the test data from the document store:
eval_labels = document_store.get_all_labels_aggregated(drop_negative_labels=True, drop_no_answers=True)
The labels are actually MultiLabel objects that contain a list of possible labels for each query, complete with answers, answer spans and the text that contains the answer.
We’re ready to run our pipeline in evaluation mode. Just as with the run() method, we are able to pass top_k parameters. For the retriever, top_k specifies the number of documents to return; for the reader, it’s the number of answers:
eval_result = pipeline.eval(labels=eval_labels, params={"Retriever": {"top_k": 5}, "Reader": {"top_k": 4}})
We’ll take an in-depth look at the content of eval_result in the next section.
Investigating the evaluation results
The eval_result above is a dictionary-like EvaluationResult object with two pandas dataframes. One contains the results of the retriever, the other the results of the reader. This is how to access them:
retriever_result = eval_result["Retriever"]
reader_result = eval_result["Reader"]
Apart from the node’s predictions and the expected documents and answers, the two dataframes contain a lot of additional information, for example:
- type and node: the type depends on the node; it is “answer” for the reader node and “document” for the retriever node
- rank: a result’s position in the list of results. For example, the top document/answer has rank 1
- document_id: the ID of the retrieved document
- gold_document_ids: a list of the documents that contain the gold answers
In addition, there are several columns with node-specific metrics. For the retriever node, these are:
- gold_id_match: can be either 0 or 1 and indicates whether the retrieved document matches the gold document
- answer_match: can be either 0 or 1 and indicates whether the document contains any of the gold answers
For the reader, the relevant metrics are:
- exact_match: can be either 0 or 1 and indicates whether the predicted answer matches one of the gold answers
- f1: this metric describes the extent of the overlap between predicted and gold answers in terms of tokens. It can have any value between 0 and 1. Note that when there are several gold answers, only the highest-scoring prediction-answer pair is taken into account. The same is true for the next metric
- sas: the semantic answer similarity metric indicates how congruent the predicted answer is to the gold answer semantically. It can have any value between 0 and 1. This metric is optional and requires a pre-trained language model
The reader results dataframe also contains the answer’s positions within the document, for both the gold and the predicted answers. To see a full description of the underlying schema, have a look at the documentation in the source code. If you want to see the dataframes in action, you can check out the tutorial notebook.
Filtering for queries
The pandas dataframe format makes it easy to zoom in on the results that interest you. For example, if you want to know how well the system handled a specific query, you can make use of pandas’ extensive selection capacities.
query = "who is written in the book of life"
retriever_book_of_life = retriever_result[retriever_result["query"] == query]
This will return a subset of the dataframe with only the results for the query you’re interested in. Of course, you can do the same for the reader results:
reader_book_of_life = reader_result[reader_result["query"] == query]
Other useful methods
EvaluationResult is a convenience class that helps you handle the results of an evaluation as intuitively as possible. Here’s what else you can do with this handy class:
Save and load
Depending on the size of your evaluation dataset, evaluation can be time-consuming. To avoid having to recompute them every time, the results in EvaluationResult object can be stored as CSV files (one per node), from which you can reload them:
eval_result.save("../")
saved_eval_result = EvaluationResult.load("../")
Compute aggregate metrics
Individual results are important as they can give you insight into how your system is working. But ultimately, you’ll want to compute the quality metrics for the entire evaluation dataset. You can obtain all the different metrics for both components of the pipeline with one single call:
metrics = saved_eval_result.calculate_metrics()
The metrics object contains different scores for both reader and retriever nodes. For the reader, these are simply the metrics discussed in the previous section — exact match (EM), F1 and, optionally, SAS — aggregated and averaged over the entire evaluation dataset.
For the evaluation of the retriever, this step introduces a few additional metrics, some of which take into account the notion of “rank,” i.e., the position of a correct document in the ordered list of retrieved documents. For example, the reciprocal rank metric uses the notion of a multiplicative inverse: it is 1 if the correct document is the first result in the retrieved list, ½ if it’s second, ⅓ if it’s third, and so on. The mean reciprocal rank is then the reciprocal rank averaged over the entire dataset. To learn more about retriever metrics, have a look at the documentation.
The individual metrics can be accessed by first passing the node and then the metric that you’re interested in. For example, to access the mean reciprocal rank score of the retriever node, you can do:
metrics["Retriever"]["mrr"]Simulate lower top_k
If your top_k values are higher than 1, you can experiment with lower values for both the retriever and the reader. This saves you the computationally expensive step of re-running pipeline.eval() with different top_k values. Use the simulated_top_k_reader and simulated_top_k_retriever parameters to pass the desired value to the calculate_metrics function. For example, to retrieve only three documents and return only one answer, you can do:
metrics = eval_result.calculate_metrics(simulated_top_k_retriever=3, simulated_top_k_reader=1)
With these settings, do you expect higher or lower scores?
Display wrong predictions
Typically, you want your system’s predictions to match as many of the gold labels as possible. But the most interesting examples are those where the system did not predict the right answers. That’s because these errors help to identify and improve the pipeline’s weaknesses. Another cause for “wrong” predictions might be incorrect labels, which we’ve gone into at this meetup.
To only return your system’s errors, call wrong_examples() with the node that interests you as an argument:
eval_result.wrong_examples('Reader')Generate an evaluation report
An evaluation report is a handy overview of your entire pipeline. As such, it does not belong to EvaluationResult, but to the Pipeline class itself. Here’s how to use it:
pipeline.print_eval_report(eval_result)
It will return a sketch of the pipeline and its nodes, a few quality scores and a couple of wrongly predicted examples from each node. Look at this useful sketch of the pipeline’s architecture:

Integrated or isolated evaluation?
So far, we’ve been looking at evaluation in the integrated mode. In this mode, you evaluate the pipeline as a whole, treating it like a black box where you can only see the input and the output. Integrated evaluation simulates the experience of open-domain question answering, where the pipeline has to a) retrieve the correct documents from a large collection of texts and b) select the correct answer from the retrieved documents.
Alternatively, you can run a node in isolation to investigate its performance independent of the previous node. This is analogous to closed-domain question answering, where there’s only a reader module. In isolated mode, the reader’s input doesn’t depend on the output (and thus the quality) of the retriever. Instead, the reader receives the “gold” document and scans it for the right answer:
eval_result_with_upper_bounds = pipeline.eval(
labels=eval_labels, params={"Retriever": {"top_k": 5}, "Reader": {"top_k": 5}}, add_isolated_node_eval=True
)
Evaluating the reader in isolation — and comparing it to the results in integrated mode — gives you an idea of how well the retriever is contributing to the pipeline’s overall performance. If the reader performs much better in isolated than in integrated mode, that means that the documents it receives from the retriever are not very well selected. In this case, you can take a closer look at the retriever and try to improve its quality, for instance by increasing top_k or by using a different retrieval model. If, however, the reader displays similar scores in both modes, focusing on the reader would be the way to go if you want to improve your pipeline’s overall quality.
Get started
Time to start evaluating your extractive QA pipelines with our new eval() method! (Feel free to try out the evaluation tutorial first.) If you want to share your results with the Haystack community, why not join our Discord? Discord is also the perfect place to ask questions and receive support from other users, or directly from our team members.
If you want to learn more about the Haystack framework, head over to our GitHub repository (make sure to leave us a star if you like what you see), or check out our documentation.
Curious about building AI Apps and Agents?

Table of Contents