TLDR
Key Metrics:
Back in the days of BERT-like language models, we talked a lot about fine-tuning. The process of further adapting a language model to a particular task or domain often significantly improved its performance. This was achieved by subjecting the pre-trained model to additional training steps on smaller, curated datasets.
More recently, artificial intelligence (AI) practitioners have turned their attention to fine-tuning in the context of large language models (LLMs). Their hope is that this will result in LLMs that are more knowledgeable, more compliant in the type of output they produce, and overall better at helping their organization accomplish specific tasks.
But fine-tuning large language models isn't a one-size-fits-all solution for making them work for your enterprise. In this blog post, we'll look at how fine-tuning works, when it's necessary, and when you're better off using alternatives. In particular, we'll compare fine-tuning to retrieval augmented generation (RAG): a technique that allows you to use your own data without ever touching the parameters of the LLM.
What is fine-tuning?
Fine-tuning is a well-established technique in machine learning. Instead of training a model from scratch, which can cost millions of dollars in hardware alone for large language models, you can take a pre-trained model and adapt it to better fit your own data. The reason is that a pre-trained model has already learned a lot about language and the world at large. Therefore, you need much less data to make it work for your own use case than if you were to train a model from scratch.

Today, you can use a service like Hugging Face’s AutoTrain or OpenAI’s API to fine-tune an LLM using data that most accurately represents how the final application will be used. For example, if you’re an engineer at a bank looking to leverage the capabilities of an LLM in customer service, you can fine-tune a pre-trained model using data from real customer interactions that contain the kind of financial jargon you want the model to learn.
Fine-tuning, by the way, is also a big part of creating instruction-following LLMs in the first place. Getting a base model like GPT-4 to interact with humans the way it does in the ChatGPT application requires different fine-tuning steps. See our introduction to large language models to learn more.
Different types of fine-tuning
There are two main goals you can achieve by fine-tuning.
- Domain-specific fine-tuning - You can tune your LLM for a specific language domain or tone. For example, a pharmaceutical company's internal knowledge base may use different terminology than the LLM's training data. Or, if you generate news reports, you might want to mimic the tone of a particular author.
- Task-specific fine-tuning - On the other hand, fine-tuning can help improve performance on very specific, narrow tasks that benefit less from the generative nature of an LLM, such as classification, entity recognition, or regression. This type of fine-tuning requires an annotated dataset that matches the input sample data and the desired labels. However, fine-tuning the LLM in this way reduces its overall capabilities - a phenomenon known as the "alignment tax."
So what about RAG?
RAG and fine-tuning are often compared, and for good reason. While the two techniques are not exactly complementary, they represent two very different approaches to feeding your proprietary data into an LLM.
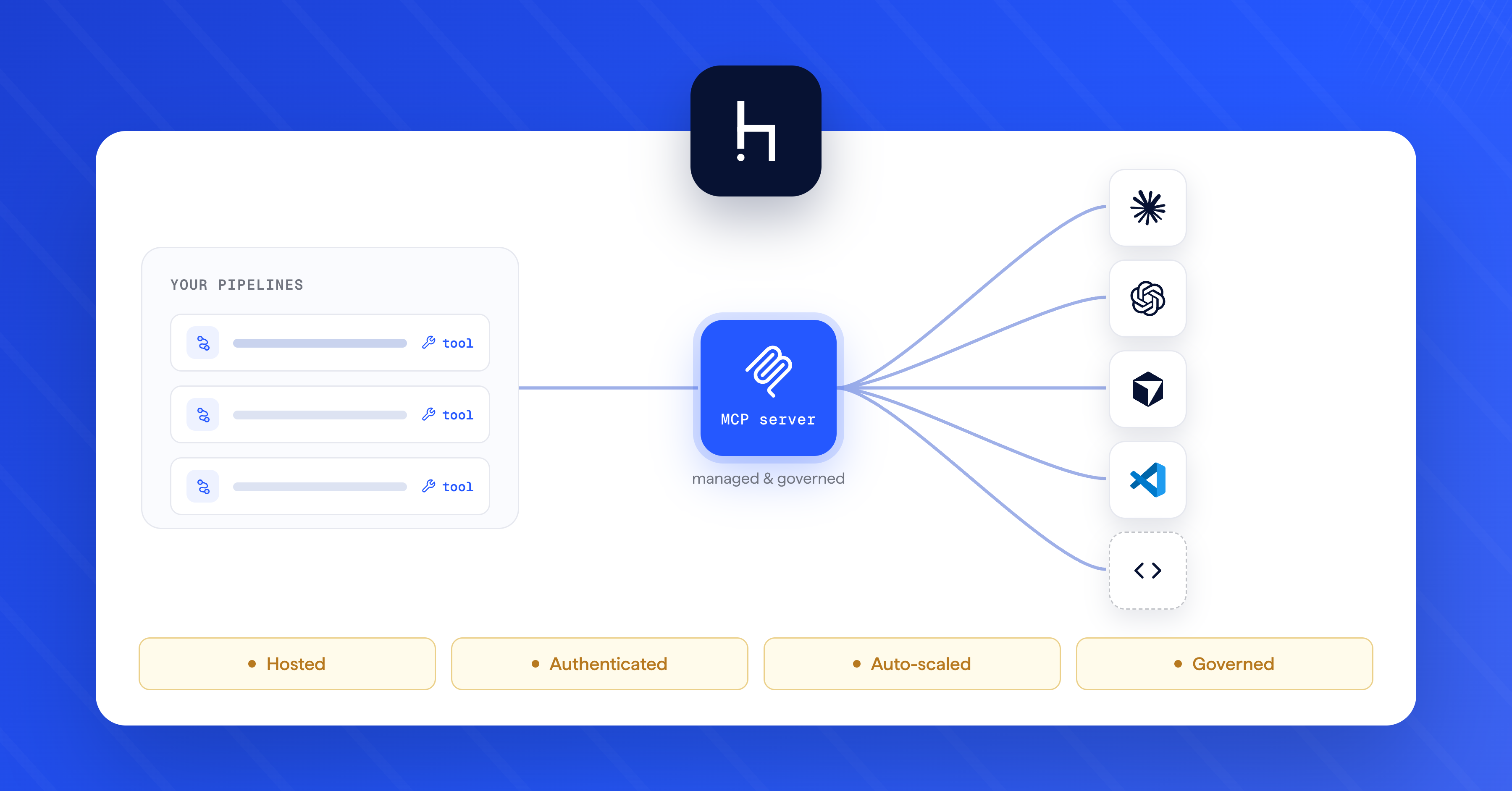
In RAG, you use a retrieval component to extract the right documents from your own database and place them in the prompt to the LLM. You can then instruct the model to base its answer on this new context.

RAG takes advantage of the modularity of modern language processing, which allows developers to wrap multiple components into a pipeline that processes input sequentially. This concept can be extended to create ever more powerful and flexible systems.
The promises of fine-tuning under the microscope
As described above, fine-tuning can help you to train your model in very specific language domains, or to classify textual data. But one thing fine-tuning is not ideal for is injecting your company-specific data into the LLM. Here are the main reasons why:
- Obsolescence. Your database is likely to change over time, which means that your fine-tuned model will become outdated and require repeated fine-tuning.
- Cost. Not only do you have to pay for the fine-tuning itself, but you'll also have to spend time and resources curating the datasets that this process requires. As if that were not enough, a fine-tuned model is much more expensive to query than the base model.
- Hallucinations. Fine-tuned LLMs can hallucinate (that is, fabricate facts) just like any other generative language model.
- Security. Many organizations with high security requirements are reluctant to send their proprietary data to third-party vendors like OpenAI. This issue becomes even more pertinent in the case of fine-tuning: you need to trust the platform to keep your fine-tuned model weights – which contain sensitive information – secure.
Based on these observations, it seems that fine-tuning is a less-than-optimal solution for most use cases. Fortunately, RAG is a promising alternative.
Retrieval augmentation for the win
The great value proposition of retrieval augmentation is that it allows your LLM-powered application to always access the most up-to-date information without any expensive fine-tuning steps. All you have to do is ensure that the documents in your database are updated regularly. Since the retrieval component of your RAG application is connected to this database, it can always access the latest information and pass it on to the LLM.
Your retrieval engine is also much easier to evaluate than an LLM: using metrics such as recall, you can quickly find out if it is retrieving the right documents from your database. And if it's not? Well, it might be time to fine-tune your retrieval model. Because these models are much smaller than LLMs, you can do this within your own infrastructure rather than through a third party.
Another element that contributes enormously to the overall performance of your RAG application is the prompt. Depending on the LLM's context window, you can package documents, detailed instructions, and examples of how your output should look in your prompt, which you then pass to the LLM. Prompt engineering is an art in itself, and to ensure the best results, you should also regularly evaluate and update your prompts.
To combat the notorious LLM hallucination, you can instruct the model to add citations – references to your real-world documents – to each of its claims. If that is not enough, you can even install a hallucination detector component that can independently evaluate whether the LLM's output is based on the retrieved data.
The best possible user experience
Regardless of which technique you choose, the key is to make sure you deliver the best possible experience to your end users. In our experience, about 90 percent of enterprise LLM applications benefit from the flexibility and modularity provided by retrieval augmented generative pipelines with carefully designed prompts.
For the rest, it's great news that fine-tuning is now possible, even for large language models. Our recommendation: if a pure RAG-based solution can't capture the idiosyncratic language of your industry, or fails to produce the kind of output your application requires, then fine-tuning is the way to go. And if your application still requires current information, you can easily combine fine-tuning and RAG for the best of both worlds.
Curious about building AI Apps and Agents?

Table of Contents