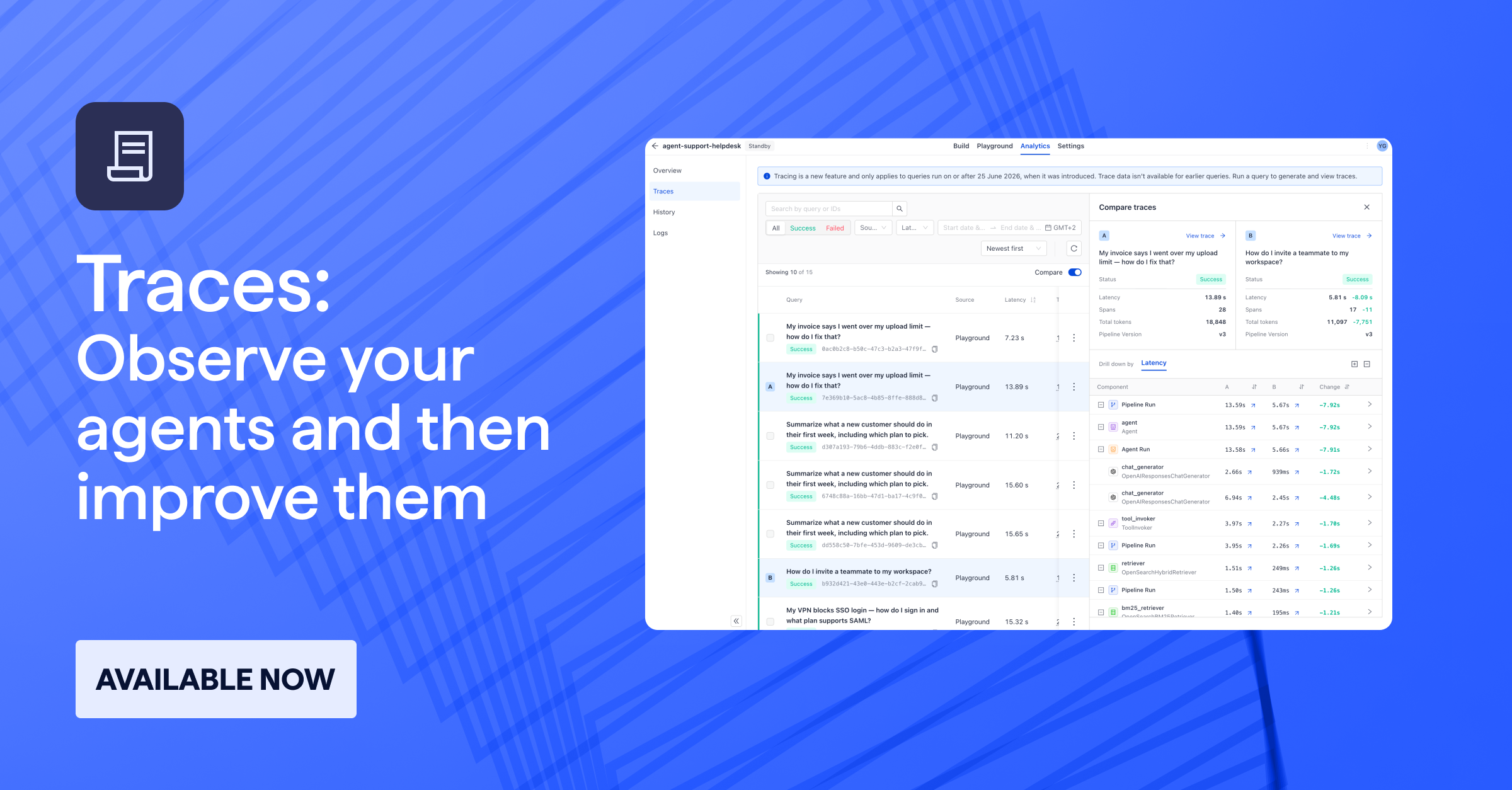
TLDR
Key Metrics:
In our recent post on evaluating a question answering model, we discussed the most commonly used metrics for evaluating the Reader node’s performance: Exact Match (EM) and F1, which measures precision against recall. However, both metrics sometimes fall short when evaluating semantic search systems. That’s why we’re excited to introduce a new metric: Semantic Answer Similarity (SAS). We first introduced SAS in August of 2021 with a paper that was accepted at the conference for Empirical Methods in Natural Language Processing (EMNLP).
Like the language models that we employ in question answering and other NLP tasks, the SAS metric builds upon Transformers. Rather than measuring lexical overlap, it seeks to compare two answer strings based on their semantic similarity, allowing it to better approximate human judgment than both EM and F1. In this blog post, we’ll show you how to use SAS in Haystack and provide some interpretation guidelines.
Why we need metrics
When we build, train, and fine-tune language models, we need a way of knowing how well these models ultimately perform. In an ideal world, we would have enough time to evaluate our machine learning system’s predictions by hand to get a good understanding of its capabilities. And it does make sense to check a subsample of answers manually, even if only to get a feel for the system.
But it’s clearly beyond our capacity to evaluate hundreds or thousands of results each time we want to retrain a model. That’s why we rely on metrics to tell us how well — or how poorly — a model is doing. Both EM and F1 measure performance in terms of lexical overlap. EM is a binary metric that returns 1 if two strings (including their positions in a document) are identical and 0 if they aren’t. F1 is more lenient: It provides a score between zero and one that expresses the degree of lexical overlap between the correct answer and the prediction.
What’s wrong with the existing metrics?
A Transformer-based language model represents language by abstracting away from a word’s surface form. BERT, RoBERTa, and other common models represent tokens as vectors in a high-dimensional embedding space. Their aim is to encode the meaning of a word rather than its lexical representation. A well-formed deep language model can faithfully represent linguistic phenomena like synonymy and homonymy (where multiple words might look or sound the same but have different meanings).
Such properties of natural language mean that we can express a single piece of information with completely different sets of words. Consider the sentence, “The Queen is visiting the U.S.” from a British newspaper. You might find that same information expressed as: “The British monarch is traveling to the United States.” A traditional metric will return a similarity score of zero for the two sentences (F1 performs stop-word removal during preprocessing, so words like “the” and “is” are not taken into account).
Introducing Semantic Answer Similarity
To address the need for metrics that reflect a deeper understanding of semantics, several Transformer-based metrics have been introduced over the past years. Our SAS metric is the most recent addition. For a detailed description of SAS, see our paper. In the paper, we show that the metric correlates highly with human judgment on three different datasets. We’re happy to announce that the paper was accepted at the 2021 EMNLP conference — one of the most prestigious events in the world of NLP.
SAS uses a cross-encoder architecture that accepts a pair of two answers as input — one answer being the correct one, the other the prediction by the system. To assess the similarity of the two strings, SAS leverages a pre-trained semantic text similarity (STS) model. The model is language-specific.
Importantly, the model learns to distinguish which words in a sentence contribute most to its meaning, eliminating the need for a preprocessing step like stop-word removal. When applied, the SAS metric returns a score between zero (for two answers that are semantically completely different) and one (for two answers with the same meaning).
Using SAS in Haystack
To evaluate your question answering system with the new metric, make sure that you’re using the latest release of Haystack. We’ve updated our QA system evaluation tutorial to cover the new SAS metric.
If you want to follow along with the below code example, simply copy the notebook and open it in Colab. The SAS metric can be used to evaluate the Reader node or the entire pipeline, so we initialize the SAS model together with the EvalAnswers() node:
from haystack.eval import EvalAnswers
eval_reader = EvalAnswers(sas_model="sentence-transformers/paraphrase-multilingual-mpnet-base-v2", debug=True)
We set the debug parameter to True so that we can investigate the results later and get a better understanding of how the similarity metric works internally.
Once initialized, we place the node in an evaluation pipeline, right after the reader node (check out the tutorial for the full code). We can then simply run the entire pipeline to evaluate it on the test dataset.
After running the pipeline, we investigate the log to understand how SAS operates compared to the other two metrics — eval_reader.log stores all the queries, their correct manually annotated answers, and the answers predicted by the system.
Let us look at select examples where we compare SAS and F1 scores.
Example 1
Question: Where does the last name Andersen originate from?
Correct Answer: Danish-Norwegian patronymic surname meaning ”son of Anders”
Predicted Answer: Denmark
F1: 0.0
SAS: 0.47
In this example, we can see that F1 assigns an undeservedly low score to the correct answer. One could even argue that the short and concise answer “Denmark” is better suited to the question than the rather long correct answer from the evaluation dataset. Be that as it may — the SAS score does a good job at recognizing that even though the two answers don’t share any lexical overlap, they’re close semantically.
Example 2
Question: How much did Disneyland Paris cost to build?
Correct Answer: a construction budget of US$2.3 billion
Predicted Answer: US$2.3 billion
F1: 0.57
SAS: 0.69
F1 is calculated based on precision and recall. In this example, precision is 1 (all the tokens in the predicted answer are part of the ground-truth answer), but recall is lower than that (not all the ground-truth tokens are part of the predicted answer), which drags down the score. SAS on the other hand assigns a decent score of nearly 0.7 to the answer, recognizing that it captures the most significant part of the correct answer. The next example is a bit trickier.
Example 3
Question: Where was the capital of the Habsburg empire located?
Correct Answer: Vienna, except from 1583 to 1611, when it was moved to Prague
Predicted Answer: Vienna
F1: 0.15
SAS: 0.64
In this example, the model again predicted the most relevant part of the answer, but this time, the omitted part carries an important bit of information, too. However, the F1 score seems unfairly low again — and in most situations, a user would probably be happy with the predicted answer.
Example 4
Question: Who told the story of the Prodigal Son?
Correct Answer: Jesus Christ
Predicted Answer: Reverend Robert Wilkins
F1: 0.0
SAS: 0.48
While the predicted answer is not as wrong as it might look at first glance, it bears no similarity to the ground-truth. However, SAS awards it a score of close to 0.5. In this case, F1 seems better at flagging a wrong answer.
How to work with SAS
By now we’re aware of SAS’s strengths in terms of semantic similarity. But as the last example shows, there are cases where the model might interpret “semantic similarity” a bit too broadly. While we cannot be entirely sure how the model arrived at its score, it seems that it awards a relatively high similarity to the strings “Jesus Christ” and “Reverend Robert Wilkins” based on the simple fact that they both refer to persons. In our experiments, we’ve seen similar results for different dates and numbers that nonetheless received a rather high scoring by the SAS metric.
We might argue that this means that the model understood the question. After all, it did not return random words, but a somewhat adequate response that highlights the same part of speech as the correct answer. In most cases, though, such a prediction would still count as plain wrong. This is something that we’d like to see reflected in a smart similarity metric.
As we’ve seen, SAS is not (yet) a perfect QA metric — but neither are F1 and EM. In our experiments, we found that SAS can cover a lot of the situations where the other two metrics are incorrect. It shows a high correlation with human judgment, which ultimately is the best metric of whether a system is helpful or not.
SAS helps to evaluate question answering systems better, and it might also be helpful in a situation where dataset contains multi-way annotations (there are multiple correct answers for the same question). SAS takes all semantically similar answers into account, so there is no need to label each and every correct answer. While SAS doesn’t address training directly, we’ve been also discussing some ideas in regards to how we could leverage SAS for labeling and training as well.
In the majority of use cases, you’ll want to generate scores using all the three metrics. Using SAS in conjunction with EM and F1 can give you a better understanding of how well your system is doing. For example, SAS can help you identify samples where F1 might be misleading. If the values returned by F1 and SAS are relatively similar, the probability of both being right is higher.
Get started with Haystack and SAS
To start experimenting with the new Semantic Answer Similarity metric, head over to our GitHub repository — and if you enjoy using Haystack, feel free to give us a star!
Curious about building AI Apps and Agents?

Table of Contents

.png)