Access world-class, thorough documentation with lots of practical examples, so that users can start building and integrating high-quality features immediately.
HAYSTACK
THE PRODUCTION-GRADE
OPEN SOURCE AI ORCHESTRATION FRAMEWORK
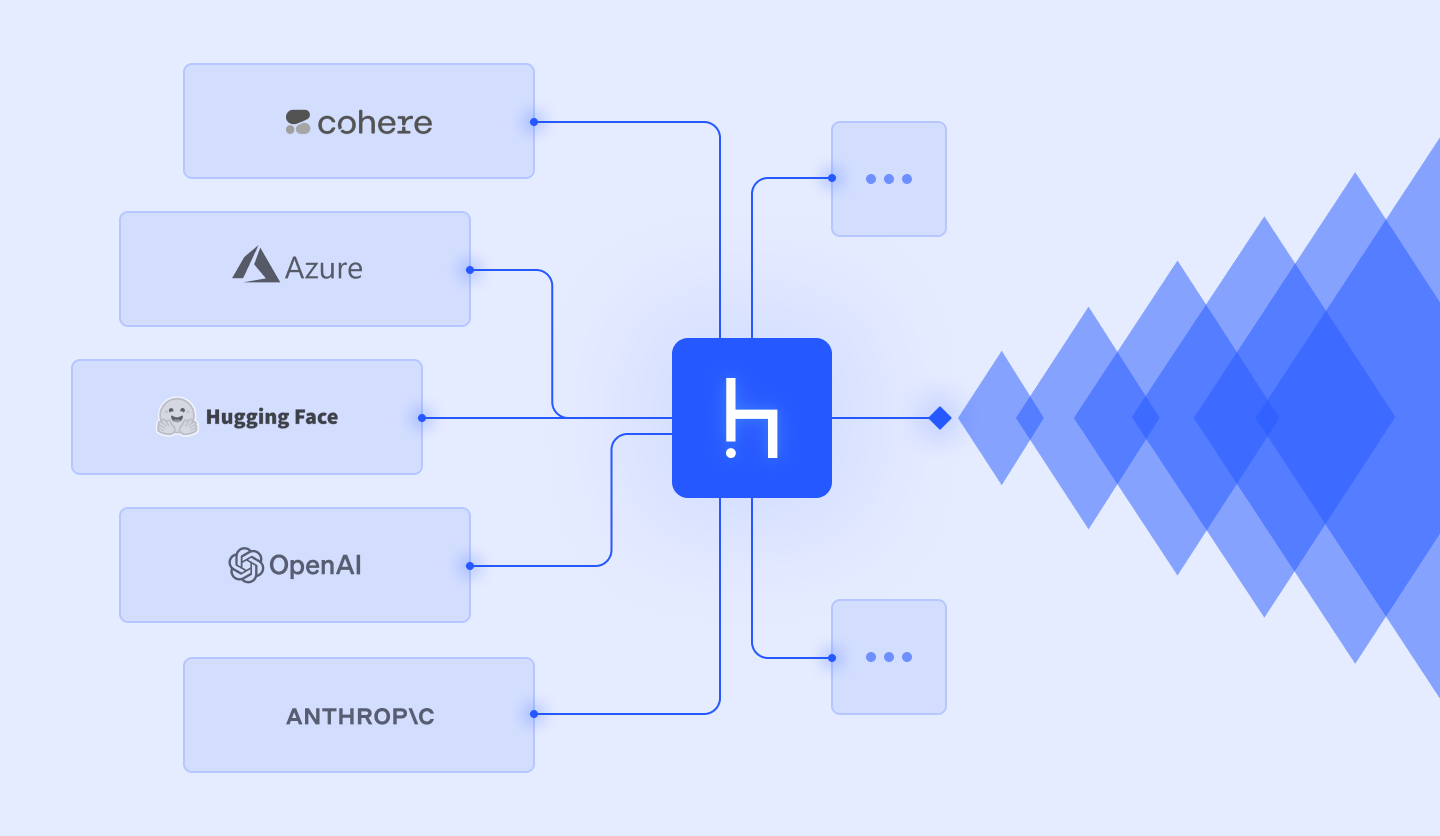

Build custom AI agents and applications with our intuitive and comprehensive framework for modular AI orchestration.
Used by Leading Enterprises Everywhere

















%20copy%207.png)
Not All Frameworks are Created Equal
Haystack puts AI developers in control with clear documentation, modular blocks, and production-ready design. No unnecessary complexity, no rigid constraints.
the ultimate framework for ai ORCHESTRATION
Haystack is an open source Python framework that stands out for orchestrating and building custom, production-grade AI agents and applications, offering extensive documentation, modularity, customizability, serialization, and robust production support—making it the go-to choice for building production-grade AI solutions.
Comprehensive Documentation

Composable Pipelines
Haystack is deeply modular, so in addition to starting with pre-built pipelines, you can build highly customized graphs for your preferred architecture. This flexibility also allows you to extend your initial prototype in multiple directions by adding, removing, or updating components to solve your use cases with precision.

Custom Components
Write your own custom code, leverage Model Context Protocol (MCP), and retain complete control over their applications. To meet your organization's unique or legacy requirements, you can add your own logic and seamlessly integrate it into your Gen AI pipelines.

Components Library
Haystack has a large library of components that can perform different tasks. They can manage embedding and retrieval, large language models, routing inputs, guardrails, or invoking external tools. You can easily build modular pipelines by connecting components to customize your agentic, RAG, search, IDP or other use cases.
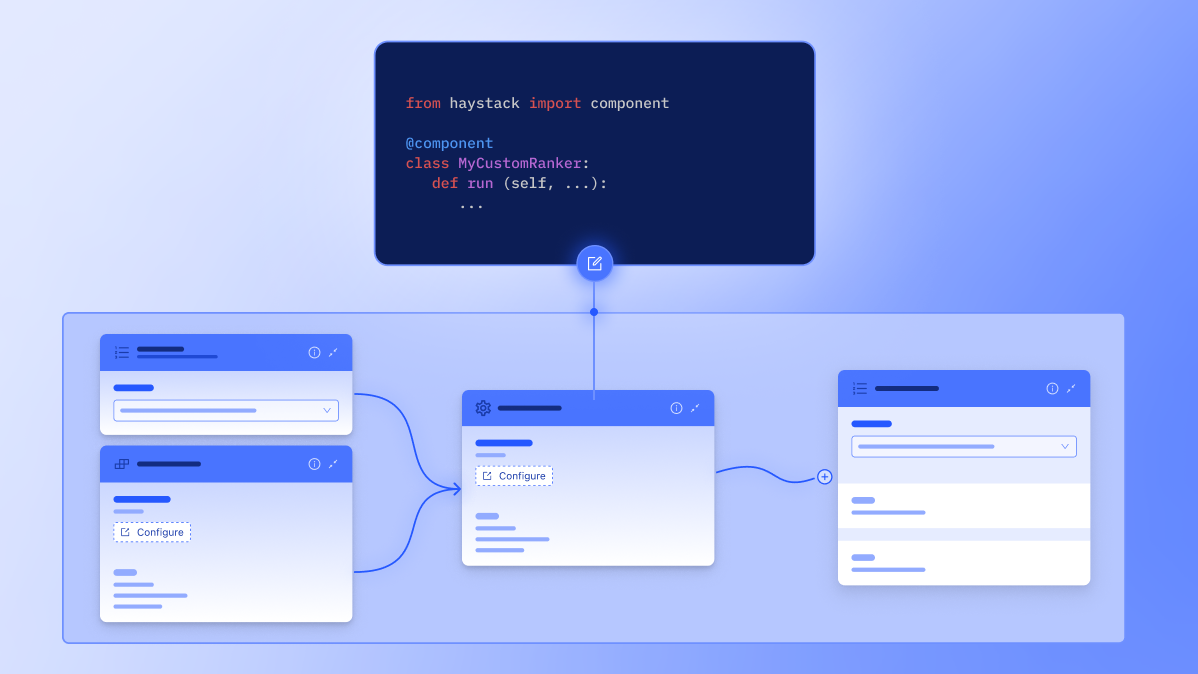
Production-Grade Stability
Haystack pipelines are fully serializable so you can store and manage pipeline configurations externally and deploy in any environment. Logging and monitoring integrations give you the transparency you need. Our deployment guides walk you through full-scale deployments on all clouds and on-prem.

The haystack ecosystem
Haystack, the leading open-source framework for production-grade LLM orchestration, is the foundation of the Haystack Enterprise Platform.

AI Orchestration Framework
Open-source AI framework for building production-ready pipelines with agents, RAG, and more - supported by robust documentation and an active enterprise community.

AI Orchestration Framework
& Enterprise Support
& Enterprise Support
Accelerate and upskill with:
- Private consulting and support
- Pipeline and deployment blueprints
- Flexible expansions

AI Orchestration Platform
& Enterprise Support
& Enterprise Support
Platform and infrastructure for AI and business teams to build and run production AI.
- Visual, code-aligned pipeline design
- Data, retrieval, and testing workflows
- Secure access controls and auditability
- Scalable cloud or on-prem deployment
Try the Haystack Enterprise Platform for free: Sign up for the trial
The Community for Enterprise AI Builders
"Haystack allows its users a production ready, easy to use framework that covers just about all of your needs, and allows you to write integrations easily for those it doesn’t."

Josh Longenecker
Generative AI Specialist, AWS
"Haystack's versatility and extensive documentation make it an excellent choice for both beginners and experienced developers looking to implement RAG systems."
Sebastian Petrus
Assistant Professor of AI and ML, University of Waterloo
"While every framework has its strengths and learning curve, Haystack's design philosophy significantly accelerates development and improves the robustness of AI applications, especially when heading towards production. The emphasis on explicit, modular components truly pays off in the long run."
Rima Hajou
Lead Data Scientist, Accenture


%20copy%202.png)

.png)


Featured integrations












FAQ
What is Haystack?
Haystack is an open-source Python framework widely used in enterprises to build custom, production-grade AI agents and RAG applications. It enables modular pipeline building on top of a rich library of integrations, with the flexibility to add custom components and new tools such as MCP.
With robust documentation and production-ready features like serialization, logging, and well-defined APIs, Haystack supports reliable deployment across cloud and on-premise environments.
What is an LLM orchestration framework?
An LLM orchestration framework, like Haystack, provides the tools and abstraction layer needed to build and manage advanced AI workflows. It supports capabilities like chaining prompts and models, retrieving data from external sources, integrating APIs, and maintaining statefulness across interactions. These frameworks also include templates, monitoring, evaluation, and deployment tools to streamline generative AI application development.
Who is Haystack for?
Haystack is designed for a wide range of users, including AI engineers, developers, data scientists, and software developers seeking to build scalable, customizable AI solutions. It caters to technical experts who want fine-grained control over AI workflows and newcomers looking for an intuitive framework to get started with LLM-powered agents and applications.
Why do developers choose Haystack?
Developers choose Haystack for its modular approach to AI solution development, offering fine-grained control, production readiness, and seamless integration with state-of-the-art AI models. With clear, well-maintained documentation and a strong community of enterprise developers, Haystack enables fast iteration and scalability, helping teams build AI solutions that are adopted and deliver real-world impact.
How does Haystack enable production-ready AI?
Haystack’s modular architecture, robust documentation, and enterprise community contributions provide fine-grained control for building and scaling custom AI agents and applications. It supports seamless integration with data sources, AI models, and other compound AI components, ensuring enterprise-grade performance, scalability, and reliability in real-world deployments.