
Automate loan processing, compliance audits, and financial reporting for enhanced accuracy and efficiency.
Intelligent Document Processing Solutions that Adapt to You






.webp)
%20copy.webp)
%20copy%203.png)

%20copy%202.webp)
%20copy%206.png)


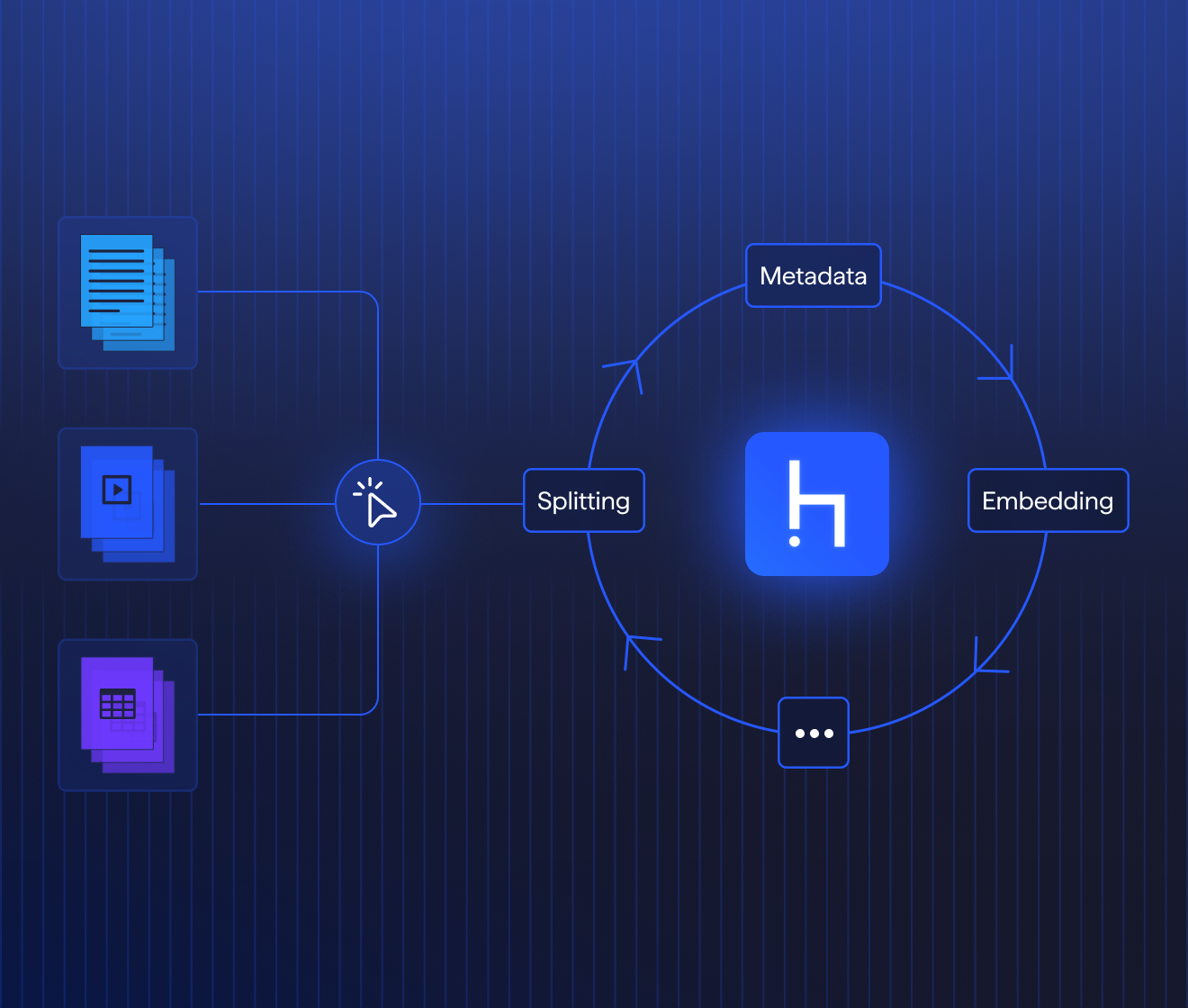
Turn documents into decisions – The New Way.
Beyond traditional IDP: Handle any document, any question, your way.
Streamline financial services
Enhance legal operations
Accelerate contract reviews, due diligence, and case preparations with automated document analysis.
Optimize healthcare processes
Manage patient records, insurance claims, and clinical trial documents for improved data handling and compliance.
Simplify insurance workflows
Expedite claims processing, policy administration, and underwriting while reducing manual effort.
Ensure regulatory compliance
Automate the extraction and analysis of safety certifications and inspection reports to maintain standards in regulated industries like food safety.
SCALABLE, SAFE AND SECURE
Open Source Foundation
Built on Haystack, the trusted open-source framework for production-ready LLM applications.
Data Privacy Assurance
Your data remains private and isn’t utilized for training your choice AI models.
Flexible Identity Management
Seamlessly integrate with your Identity Provider and configure Single Sign-On (SSO) with SAML support for tailored role access.
Flexible Deployment
Deploy to the cloud, VPC, or on-premise. It's your AI, you choice.
Enterprise Support
Dedicated support from our security and infrastructure experts, with guaranteed response times for critical issues.



FAQ
What is Intelligent Document Processing (IDP)?
The next generation of Intelligent Document Processing (IDP) leverages Gen AI to extract, organize, and analyze data from enterprise documents such as contracts, reports, policies, and applications. Modern LLM-powered IDP solutions significantly outperform previous generations by handling more complex document structures, formats, and queries. With deepset, you can customize and scale IDP solutions tailored to your organization's specific workflows and requirements.
How do LLM-powered IDP solutions improve business efficiency?
LLM-powered IDP solutions improve efficiency by automating the extraction and understanding of data from diverse and complex documents. Unlike previous systems, they excel at processing unstructured data such as free text and images, and answering nuanced, contextual queries. This improves workflows like document review, memo creation, contract management, compliance auditing, and reporting, saving knowledge workers time and reducing errors.
What are the use cases for Intelligent Document Processing?
IDP is valuable for a wide range of applications, including loan due diligence, insurance underwriting, invoice processing, contract analysis, compliance monitoring, claims management, and legal discovery. LLM-powered IDP can handle diverse formats and complex, contextual questions, making it indispensable in industries like finance, legal, healthcare, insurance, and government.
How can I implement Intelligent Document Processing in my organization?
Implementing IDP involves integrating AI-driven tools into your document workflows to automate tasks like data extraction, classification, and analysis. With platforms like deepset, you can leverage LLM-powered capabilities to create scalable, efficient pipelines customized to your industry's needs and your team's expectations, ensuring precision and compliance.
How can I customize IDP to my business?
IDP customization involves tailoring AI components like document parsers, entity extractors, and knowledge retrievers to fit your unique data and operational goals. With deepset’s modular framework and LLM-powered capabilities, you can build solutions that address specific document types, formats, and query complexities while ensuring they integrate seamlessly into your existing workflows.