TLDR
Key Metrics:
Context Engineering: The Next Frontier Beyond Prompt Engineering
Over the past couple of years, building applications with large language models (LLMs) has shifted focus from prompt engineering to context engineering. In early LLM applications, users spent time crafting the perfect prompt – the exact wording or question to pose to the model. While prompts are still important, real-world AI systems have revealed a larger challenge: providing the right context to the model. Context engineering has risen to prominence in 2025 as a more holistic approach to steering AI systems, especially as we build more complex agents and enterprise applications. It addresses the question, “What information and environment should we give an AI model so that it can accomplish a task effectively?” rather than just “How do we phrase the prompt?”. In this article we will explain what context engineering is, how it differs from prompt engineering, why it’s crucial, and what techniques and concepts it involves for those building cutting-edge AI applications.
What is context engineering in AI?
Context engineering in AI is the practice of deliberately designing and managing everything the model sees or knows when it generates a response. In simple terms, context means all the information provided to the LLM at inference time – not just the immediate user query, but also the system instructions, background knowledge, conversation history, tools or functions the model can use, guardrails, and any other relevant data or logic. Instead of focusing narrowly on phrasing a single prompt, context engineering takes a broader view: consider all the data and instructions the model should have in its input before it answers, and structure those appropriately.
%20(1).png)
This approach has emerged as a response to the limitations of prompts alone. It means thinking beyond one-shot prompts and considering the holistic state available to the model. For example, if you’re building an AI assistant, the context might include the user’s query, a predefined system role (instructions about the assistant’s persona or goals), relevant facts retrieved from a knowledge base, the recent conversation history, safety instructions or policy constraints, and even definitions of tools the assistant can invoke. Context engineering is about programmatically curating this information each time the model is called, so that the model is primed to produce the most comprehensive and accurate output.
What are examples of context engineering?
Here are four practical examples of how context engineering shows up in real-world AI systems:
- Customer support chatbot: Retrieves prior ticket history and product documentation to answer user queries more accurately and with relevant examples.
- AI coding assistant: Gathers recent code edits, file dependencies, and project structure to provide contextualized code completions and refactor suggestions.
- Travel planning agent: Combines user preferences, live flight data, and calendar availability to recommend personalized itineraries.
- Enterprise agentic RAG system: Retrieves domain-specific documents and summarizes relevant sections to ground agent reasoning and actions in up-to-date, authoritative content, relevant tools, and policy constraints.
In each case, the AI system assembles and injects just-in-time context to boost performance, reduce hallucination, and improve user trust. Rather than relying solely on prompt wording, these examples highlight how context orchestration drives reliable outcomes across tasks and domains.
What is the difference between context engineering and prompt engineering?
Context engineering differs from (and extends) prompt engineering. In brief, prompt engineering focuses on crafting the text of the prompt itself – the instructions or question given directly to the model – whereas context engineering is about designing the entire environment of information that surrounds the prompt.
Some key differences include:
- Scope: Prompt engineering is about writing a good prompt for a task. Context engineering has a broader scope: it considers all inputs to the model, including the prompt, system messages, examples, retrieved data, tool outputs, guardrails, and conversation history.
- Static vs Dynamic: Prompt engineering often results in a relatively static prompt or template. You might spend time tweaking phrasing or adding examples, but once you have a good prompt, it’s reused as-is. Context engineering is dynamic and iterative – the context may be assembled on the fly for each query or each step of an agent’s reasoning. For instance, selecting which documents to retrieve or which parts of the conversation history to include is decided at runtime, not fixed in advance.
- Information vs Instruction: Prompt engineering primarily deals with how to ask the question (the wording, formatting, etc.). Context engineering deals with what information to provide alongside the question. It blends aspects of information retrieval, knowledge base integration, and state management with prompt design.
- Tools and Integration: Prompt engineering by itself doesn’t typically involve external tools or memory – it assumes a single interaction where you just feed text to the model. Context engineering readily incorporates tools, APIs, and memory into the loop. For example, context engineering will determine if the model should call a search API and then incorporate the results into the next prompt. It treats the model as part of a larger system.
What methods are used for context engineering?
Context engineering encompasses a toolkit of methods and techniques. Here are some of the key methods used to build and maintain context for LLMs:
- Retrieval-Augmented Generation (RAG): This method integrates an external knowledge source (a database or vector index of documents) with the LLM. When the model needs information beyond its built-in knowledge, a retrieval step kicks in: relevant documents are fetched (often via embedding-based similarity search) and inserted into the prompt as context. RAG is a prime example of context engineering – it supplies real-time facts or domain knowledge to the model. For instance, a legal AI assistant might retrieve the relevant case law texts (often prioritized by a re-ranker pipeline component, by recency for instance) and provide them as context so the model can give an informed answer. By engineering the context in this way, we avoid hallucinations and ensure the model’s output is grounded in up-to-date information.
- Context Generation and Summarization: Sometimes the needed context isn’t explicitly stored but can be generated or condensed from prior interactions. Context engineering often uses summarization to compress long histories or documents into shorter representations that fit the context window. For example, a chatbot could summarize older parts of a conversation or a long document and include that summary as context going forward. This preserves important information without exceeding token limits. Such context generation can also include structured transformations (like extracting key entities or facts to carry forward). These techniques fall under context processing – manipulating and distilling context to make it more usable.
- Memory Systems (Long-Term and Short-Term): Advanced AI applications maintain memory beyond a single session. Short-term memory is basically the recent conversation or state, while long-term memory might be a persistent store of facts learned or settings per user. Context engineering involves designing how the model can access this memory. For example, you might have a user profile or a summary of past interactions that is fetched and prepended to the model’s input each time. There are frameworks for building memory modules such as vector stores for semantic or episodic memory (such as embedded chat summaries) alongside structured key-value memory for explicit user facts and settings.).
- Tool Integration: Incorporating tools (also called agents using tools) is a related method. When an AI agent can use an external tool (like calling an API, running a calculator, doing a web search), the results from that tool must be inserted into the context for the next model query. Designing how the tool outputs are formatted and integrated is a key part.Tool use and context engineering go hand-in-hand: the context needs to tell the model what tools are available and include the outputs when used.
- Prompt Templates and System Instructions: Even though we’ve moved “beyond prompt engineering,” writing good system and prompt templates is still a method under context engineering. This includes creating clear system prompts that establish the role and goals of the AI, formatting guidelines for output, and example conversations. Techniques like segmenting the system prompt into sections (background info, rules, tools, desired format, etc.) help structure the context. The format in which information is given (bullet points, JSON, tagged text) can greatly affect how the model understands it.
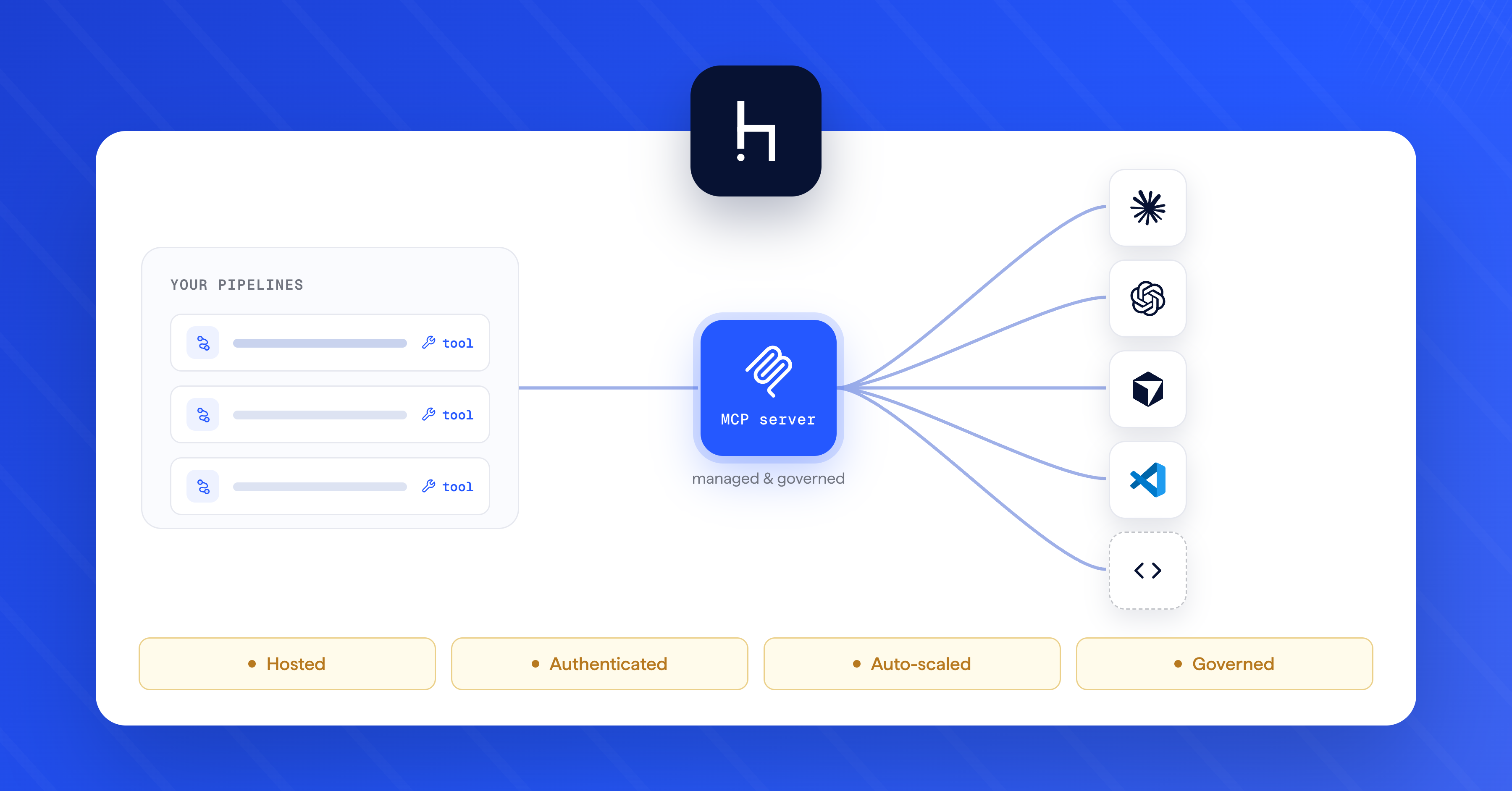
In practice, an entire context engine can be built to automate these steps. A context engine is a software system that sits between the user and the LLM, orchestrating all the context assembly in real time. It will parse the user query, retrieve needed data, aggregate everything, construct the final prompt, and then call the LLM. Many AI orchestration frameworks and pipelines (for example, those provided by open-source solutions like deepset Haystack) serve as context engines – they handle retrieval, memory, and prompt construction so developers can focus on the high-level AI system design and configuration.
In summary, context engineering utilizes a collection of methods (retrieval, summarization, filtering, memory, tool use, prompt design, etc.) that work together to feed the LLM the optimal information for each task. The right combination of these methods will depend on the application’s needs.
Why is context engineering important?
Context engineering is important because it addresses fundamental limitations and opportunities when working with LLMs:
- Overcoming Limited Knowledge and Static Training: Even the largest LLMs have a knowledge cutoff and do not have access to time-sensitive, proprietary, or situational information. Context engineering allows you to inject fresh, relevant knowledge at query time (via retrieval or tools). This bridges the gap between what the model was trained on and what it needs to know now. It’s far more efficient than expecting the base model to be omniscient or constantly retrained. In short, context engineering provides situational awareness to the AI system. In effect, context engineering gives the AI system situational awareness and allows it to operate beyond its initial training data.
- Mitigating Hallucinations and Errors: A well-engineered context can ground the model in facts, reducing the chance it will “hallucinate” answers. For example, if the model is asked about a specific product spec and you retrieve the spec sheet into context, the model is more likely to output accurate information rather than making something up. By controlling what context the model sees, you also steer it away from irrelevant or misleading information. This makes AI outputs more reliable and aligned with source truth (which is critical in domains like public sector, healthcare, law, finance, etc.).
- Essential for Complex, Multi-Turn Tasks: The more complex the task, the more the model must remember and incorporate. For AI agents that converse, plan, or take actions over multiple steps, prompt engineering alone falls short – the model doesn’t remember anything beyond its context window. Context engineering provides the memory and state management required for these agents to function. As we build agents that operate over longer sessions or perform sequences of actions, managing context (what to carry over, what to forget, what to focus on each step) becomes the key to success. Without it, the agent would either lose important information or run out of space in its context window and get confused.
- Maximizing the Utility of the Context Window: LLMs have a limited context window (think of it as their short-term memory buffer for input tokens). Simply throwing more data into the context window can hit diminishing returns – models can actually get worse at recalling specific facts as the context gets very large, a phenomenon researchers call “context rot”. Every token in context slightly taxes the model’s attention, which means irrelevant or poorly structured context can degrade performance. Context engineering finds the sweet spot where the model has exactly the information it needs, organized clearly, leading to better output.
- Consistent and Steerable Behavior: Another reason context engineering matters is that it’s a way to steer model behavior consistently. System prompts and structured context can enforce certain behavior (for example, always responding with a JSON format, or always following a company’s policies present in context). It’s much more controllable than hoping the base model will follow instructions by default. By embedding rules and role definitions in context, developers can achieve a level of determinism and consistency that prompt tinkering alone can’t.
In summary, context engineering elevates AI systems from toy demos to reliable products. It recognizes that powerful models still need the right information to solve real business problems. Many failures in AI applications trace back to context failures rather than model failures – if the model wasn’t given the necessary facts or was distracted by irrelevant text, naturally the output will suffer. Context engineering directly tackles this by ensuring the model’s limited attention is focused where it counts.
What are key concepts associated with context engineering?
Context engineering has several key concepts- and terms to be familiar with:
- Context Window: This refers to the amount of text (in tokens) an LLM can attend to in one go. It’s essentially the model’s working memory. All prompt text, instructions, and added information have to fit into this window. If you exceed it, earlier parts get truncated. Thinking in terms of the context window is crucial – you have to decide what fits and what falls out. The concept of context length and limitations like context overflow (when too much information causes important pieces to be dropped or ignored) are central considerations for context engineers.
- Relevance and Focus (Context Relevance): A key concept is ensuring relevance – the model should see information that is relevant to the query or task at hand. If irrelevant content is included, it can distract the model or cause it to produce off-target answers. Context engineering involves techniques to score relevance (e.g. using vector similarity or domain heuristics) so that only pertinent info is included.
- Few-Shot Examples: Providing examples of the task in the context is a form of prompt engineering that falls under context engineering when done systematically. Few-shot prompting means you include one or more Q&A pairs or demonstration of the task in the context, so the model has a pattern to follow. This consumes the token budget but can greatly improve performance on certain tasks by giving the model context of “how a good answer looks”.
- System vs User vs Assistant Messages: In chat-based LLM APIs, context is often segmented into different roles (system instructions, user message, assistant response, etc.). Context engineering involves understanding how to leverage the system message (to prime the model’s behavior globally) versus user messages (prompts/questions) versus assistant messages (previous answers). The system message is a powerful place to inject high-level context: e.g. your agent’s role, personality, or high-level rules. Persistent system prompts (that remain at the top of context for every query) are a common technique to ensure consistency across a session or application.
- Retrieval Index / Vector Database: When dealing with external knowledge, a concept you’ll encounter is the vector index or vector database. This is where documents are stored in embedding form to enable similarity search. Knowing how to build and query these indices is important, as it underpins RAG systems. The quality of your context often depends on the quality of your retrieval results from this knowledge store.
- Tool/Function Schema: If your AI can use tools (via function calling or an agent API), each tool has an interface or schema that needs to be communicated to the model in context. Defining clear tool descriptions (what the tool does, parameters) and including those definitions in the system context is vital so the model knows how and when to use them. Emerging standards such as the Model Context Protocol (MCP) formalize this exchange by defining a consistent way to describe tools and capabilities to models. This falls under context engineering because you are basically adding to the context the “knowledge” of what tools exist and how to invoke them. Poorly described tools (or not providing that info at all) can lead the model to misuse tools or ignore them.
All these concepts tie back to the core idea: we are effectively engineering an information environment for the AI model to operate within. Rather than treating the model as a black box that you poke with a prompt, context engineering treats it like an intelligent system component that needs a carefully constructed operating context. By mastering these concepts – from token limits to retrieval to tool contexts – developers and engineers can build AI applications that are far more robust, accurate, and aligned with their goals.
Conclusion
In the evolution of AI development, context engineering has emerged as the crucial next step beyond prompt engineering. For developers and AI engineers, this means that success lies not just in model architecture or prompt phrasing, but in how we architect the information flow around the model. By thoughtfully providing the right data, knowledge, and guidance to the model – at the right time and in the right format – we can unlock far more of its potential.
If you're looking to operationalize these ideas, Haystack by deepset provides a flexible, open framework for building context-aware LLM applications and agents. From modular pipelines to advanced retrieval, memory, and orchestration layers, Haystack is designed to support every layer of context engineering - whether you're integrating private knowledge bases, designing tool-using agents, or deploying scalable AI services in production. The Haystack Enterprise Platform takes these concepts further by placing context engineering tools within a suite of workflows that facilitate infrastructure management, user testing and evaluation, and governance.
As models grow more capable, performance gains increasingly come not from better models, but from smarter context.For developers and AI engineers, mastering context engineering is key to building robust, personalized, and production-ready systems. In a future of AI-native apps and agent ecosystems, context is not just a detail - it’s the interface that connects users, data, and intelligence.
{{cta-light}}
Curious about building AI Apps and Agents?

Table of Contents