Question Answering at Scale With Haystack
Everything you need to build a semantic search system in one open source Python framework.
21.07.20

Search has come a long way since string matching. While our workflows have adapted to this simple and ubiquitous tooling, there is a new generation of neural search technologies which is fundamentally changing the way we look for the information we need. Haystack, our open source, open-domain question answering framework, is here to give you the components to build search systems that operate, not by matching character for character, but by reading through with sensitivity to context and syntax and really making sense of the text. Just imagine having the power of a modern web search engine for your own documents!
We at deepset have worked with everything from Word2Vec and GloVe to Feed Forward networks and LSTMs. But when we saw how well Transformer based Question Answering models understood text, and how well they could respond to never seen before queries, we knew that we had to take up the challenge of making this work in industrial use cases. And so, we got to implementing the Databases that store your text, the Retrievers that speed up your queries and the APIs that allow you integrate this technology into your platforms. With Haystack, you have a curated collection of the most important advances from Natural Language Processing, Information Retrieval and Database Engineering and we can’t wait to see what you choose to build with it.
What Neural Search Can Do for You
Let’s say you want to gather information about the 2020 financial outlook of NVIDIA in a stack of documents you’ve collected. With your current tooling, you might start with a search for “NVIDIA”. But soon you find there are far more results than you really need. You might try to narrow the scope with a few more keywords like “revenue”, “increase” and “income”. But you now have documents that aren’t the right year, or only incidentally contain those words. All these queries, just to answer a question that you could very straight forwardly ask me in a sentence. So why not search directly by asking “How will revenue develop in 2020 for NVIDIA”?

With neural search systems, you can, because they understand the substance of what you’re asking and will adjust their search accordingly. When they see the word “outlook”, they will, by design, start paying more attention to words or phrases that give similar meaning. Even if some documents might call it a “forecast” and another might call it a “prediction”, a neural search system will read to find out if it’s what you’re looking for. This is not just a synonym augmented search either. These models “understand” that grammar structures sentences and text is not a bag of words. These models know that a “weather forecast” is not the same as the “financial forecast” that you’re looking for because what matters is not the form but the meaning.
This kind of language intelligence also knows how to hit the ground running. Even though natural language processing systems have always played a role in structuring text, they have traditionally needed large amounts of domain specific training to perform the task you want. Named-entity recognition systems (NER) need to know what entities you’re looking for, and document classification models need to be given examples of the categories you’re interested in. Neural search systems, by contrast, can start working for you straight away thanks to the recent advances in transfer learning. They are flexible enough that even in unseen domains they can often make sense of queries and documents. For example, you don’t always need to know what a “HP Valve” is to find out what component is connected to the “HP Valve”. The answer might be there in standard English. Nonetheless, these models can still be taught and giving them more text from your domain teaches them to become experts in the idioms and jargon of your field.
Open Source Is About More Than Just Code
It is crucially important to us that you can build a comprehensive end-to-end question answering system with Haystack alone! Everything that you need as an individual developer is and always will be open source. We want to give developers the power to inspect components, to see exactly what is going on under the hood and we want developers to be able to tweak code so that they make it work for their exact use case. There are other options out there already like AWS Kendra but Haystack framework offers the technical sophistication of the best modern systems as well as a degree of transparency that cannot be matched by the black box solutions. The abstractions that the Haystack NLP components offer are designed to be used and not hidden from the developer. It is our mission to continually empower users to understand the technologies that make Haystack so effective. You can certainly expect more articles from us in the near future shedding light on the different components. At the same time, we also know that large enterprises have additional requirements when using open source software in production and for these cases, we will offer commercial features and support that will help you operate Haystack in the enterprise context.
Haystack is also open source in the sense that it is a participant in and beneficiary of the generous and thriving open source software ecosystem. From a brief glance at our repo, you’ll be able to see how we stand on the shoulders of other open source giants and we are indebted to all the work they put into their projects. Just as they gave us the tools to build Haystack, we’d like to give back to the community and support your projects. Through regular exchange with programmers of all types, we’ve been able to get a better sense of what is needed and what problems are shared. We strive to be responsive to feedback and we look forward to your feature ideas and pull requests. Haystack is a collaborative effort to tackle the challenge of improving search and it is our goal to help you build great search systems.
Making Neural Search Scalable via the Retriever-Reader-Design
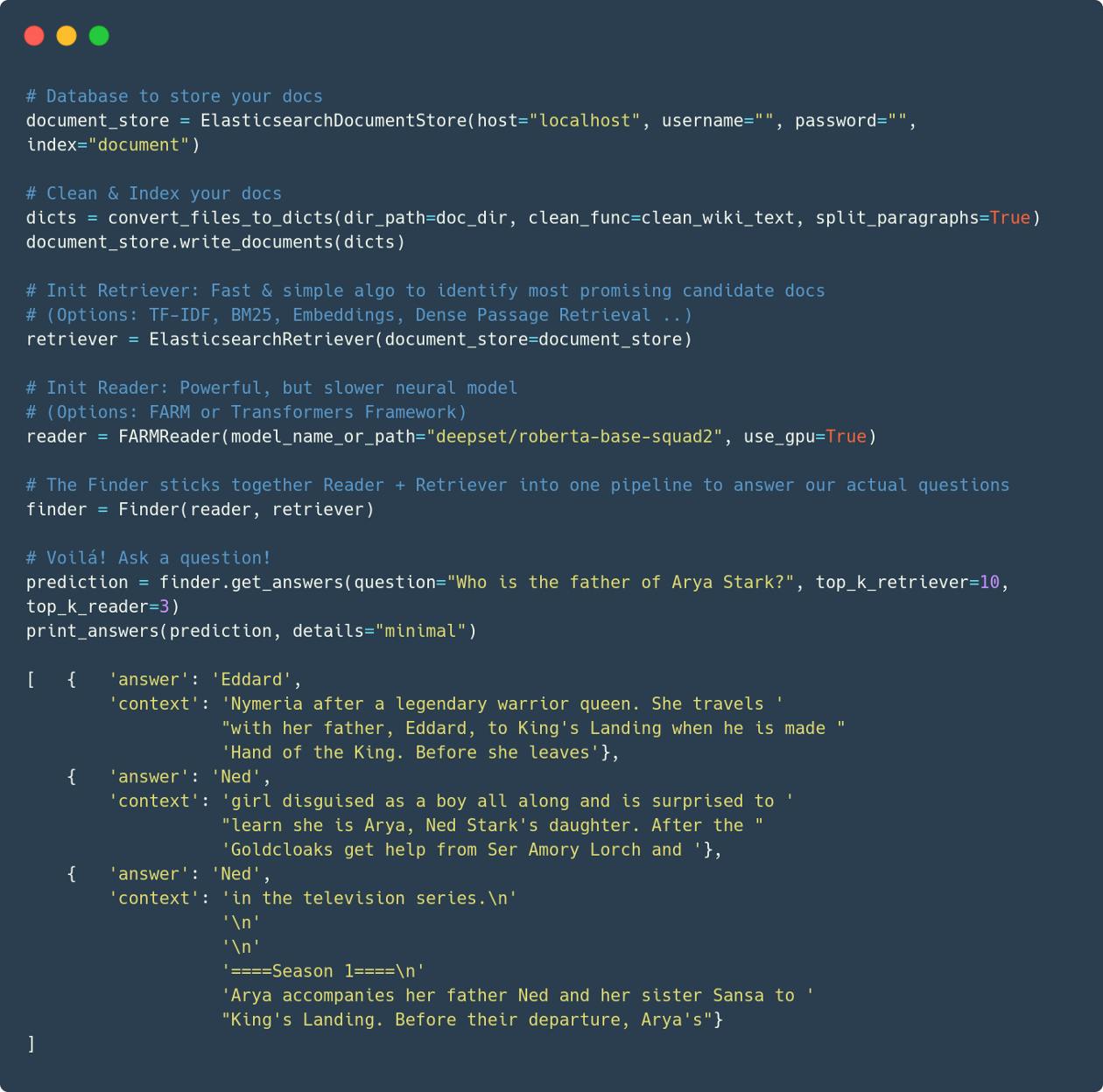
At this point, it’s worth diving into the individual parts that make Haystack work. As mentioned, Haystack is a fusion of technologies from natural language processing (NLP), information retrieval (IR) and Backend Engineering but the most important components, the Document Store, Retriever and Reader, are diagrammed below.

The Reader is the component that performs the closest analysis of the text, with great attention to syntactic and semantic detail, in order to find the span that best satisfies the question or query. Those of you coming from the world of NLP will recognize Readers as the Transformer-based Question Answering models (also known as Machine Reading Comprehension models) that tackle datasets like SQuAD or Natural Questions (find out how they work here). The quality of these models surged with the release of the BERT language model and subsequent iterations of BERT also drove up the performance of the best QA models. Thanks to the integration with Hugging Face’s model hub, Haystack users will already be able to start working with any of the question answering models that have been uploaded. Those coming from our FARM transfer learning library will also be able to continue using FARM trained models in perfect rural tranquility.
When performing queries in an open domain setting, search can be significantly sped up by first dismissing documents which have no chance of being relevant. This is done through a light-weight document filter known as a Retriever which takes all documents as input and returns just as a subset for the Reader to further process. Traditionally, they are powered by sparse methods like TF-IDF or BM25 but we are starting to see a next generation of dense methods that rely on document embeddings generated by Deep Neural Networks. Dense Passage Retrieval is one such approach that impressed us. In fact, we liked it so much that we couldn’t help but implement it and you can already try it out in Haystack!
Haystack also gives you flexibility in the kind of DocumentStore you want to use, by offering Elasticsearch, SQL or in-memory backends. There’s REST API implementation for Haystack so that you can integrate your models into any other project you have, whether you’re building a search engine, a chatbot or asking a standardized set of questions to an incoming stream of documents. We’ve also included the Haystack annotation tool so that you can get the models up to speed on the lingo in your domain with customized labeling. Of course, this is just a start and you can expect many more features in the coming months. And if there’s anything crucial to your project that we’re missing, we’d love to hear from you!
Start Using Haystack Today
More and more developers are being asked to build data platforms that enable workers to find the information they need and we have no doubt that neural search has a key role to play in this. Haystack is here for developers to start building and deploying solutions that actually reflect the current SotA and that actually fit their use case. The repository is the result of a joint effort between developers of all types to solve the problem of search and we can’t wait to see what you build with it!

