Haystack: The State of Search in 2021
How to build a semantic search engine for a better user experience.
09.03.21

Haystack was born out of the belief that with the latest research from the field of natural language processing (NLP), we can build search systems that can adapt to both your informational needs and way of speaking. Keyword search and directory filing systems have been used extensively but as the amount of digital text grows, there comes a need for more exact tools that can pinpoint what you’re looking for.
The latest NLP methods have proven to be more than capable at picking out relevant documents, rephrasing key points and creating summaries of long texts. Our goal with Haystack is to collect together these state-of-the-art technologies in the one framework so that you can build your own natural language interface into text data. Ask complex full sentence questions to Haystack and let it return to you a curated dossier of only the most useful text saving you time and effort.

Our First Retriever-Reader Pipeline
Those of you who have already tried Haystack will be familiar with the Retriever-Reader pipeline that we started with. You start by saving your data in a Document Store which can be a database in Elasticsearch, SQL, Milvus or FAISS. You use a Retriever to quickly scan through all your documents and return a handful of the most relevant ones. Then you apply the Reader and harness the power of modern Question Answering models, to closely read each sentence and highlight the parts which answer your question. Already with this design, we move beyond seeing text as a bag of words, and acknowledge that sentence structure and word meaning are integral to building a flow of ideas. We are now able to ask fully grammatical questions in our searches and tackle complex and detailed queries which were beyond the scope of CTRL + F.
Our first design definitely struck a chord with many in our community and we were very pleased to see it used to study climate hazards, search through research papers and even create a tax assistant. But over time, we were receiving ever more requests for new components and flexible ways to combine them. The tools that we are about to talk about are the fruits of the exchange of ideas, and often also the exchange of code, between us and our open source community to whom we are greatly thankful.
Generator
The way that that vital piece of information is phrased in your text might not necessarily be how you want it to be returned. Maybe the answer sentence contains more information than you need, or the answer can only be inferred after reading multiple sections of text. That’s what motivated us to include the AnswerGenerator in Haystack. Rather than simply highlighting a span of text in your documents, it will compose an answering response, based on documents that the retriever finds relevant and also the wording of the query. Our first iteration of this style of Question Answering is based on the Retrieval Augmented Generator paper released in May 2020 which has shown some very impressive capabilities. The Generator serves as a very stylish alternative to the more direct Reader and as the field of generative research grows, we believe that these models will only get more powerful.

An example where the answer can only be inferred after incorporating information from multiple sources. Generative models are likely to perform better on these cases than the extractive models found in Reader models.
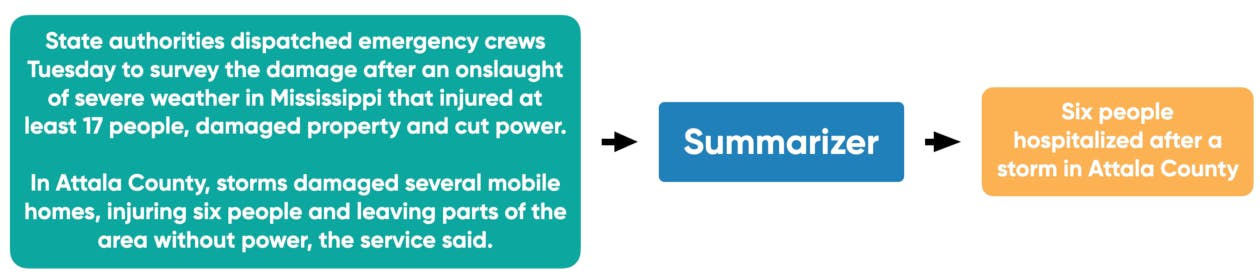
Summarizer
Summaries exist because they help us navigate large amounts of text. News articles have titles and subtitles to give a two sentence understanding about what’s to come. Academic papers start with abstracts to give you a quick glance at the questions they tackle and the success of their experiments. The value of this has not been lost on the Machine Learning experts who have developed better and better models that give you the quick and to-the-point roundup and we have incorporated them into Haystack so that you can dedicate your time to reading only the documents that matter to you. Our implementation uses the Pegasus model from Google by default but models from the Transformers model hub can be used by simply providing the model name.
Haystack Pipelines — The Connective Tissue
All of the building blocks we have mentioned so far can have their role in helping you navigate large text stacks and we don’t believe that you should have to choose between them. In fact, they are often complementary and Haystack users should have the freedom to define their own bespoke combination. Our Pipelines allow for exactly that. Using the flexibility of Directed Acyclic Graphs, you can easily stick together the building blocks to create powerful pipelines. You can route the inputs and outputs of each component, save these configurations and visualize your designs. Ultimately we’re not the ones to tell you what your search should return, we want to give you the ability to find out for yourself!

One case where we saw the need for this flexibility was in customers who didn’t want to compromise on performance when picking the right Retriever. Complex machine learning methods (e.g. Dense Passage Retrieval) and keyword based methods (e.g. the BM25 algorithm built into Elasticsearch) each have their respective advantages. With Pipelines, it is now possible to pass a query into multiple Retrievers and combine their results before routing it on to the next component. This is just one of many possible setups and we’re excited to see the creativity this will unleash when our users can mix and match modules.
What’s to Come
The list of Haystack building blocks is only going to grow and there are already many emerging methods on our radar that will help you build meaningful interfaces into your text data.
In the past few months, we have been experimenting with the idea of a Query Classifier in order to optimize your retrieval performance. It is designed to predict for a given query whether the lightweight approach will be enough or whether the heavier neural network powered machinery should be engaged, ultimately making searches generally faster and more accurate.
This philosophy of engaging the heavy machinery only when needed is also behind our interest in Reranking methods. After the Retriever has scanned for a selection of relevant documents, you might want closer analysis of just how useful they are. Using powerful transformer architectures, the latest Rerankers will perform a close reading of just the retrieved documents and give its ranking of the documents from most to least relevant, getting you to the right document quicker.
Finally, we believe that NLP is not synonymous with English NLP. We endeavour to incorporate any multilingual, cross lingual or domain specific language technologies that can extend Haystack’s search capabilities to previously unsupported languages. To that end, we are keeping an eye out on the latest translation technologies, constantly testing multilingual models and collaborating to train multilingual variants of previously monolingual models.
Conclusion
Over the course of developing Haystack, we have discovered just how different are the search needs of each individual. By contrast the limited set of search tools that are currently available do not always match their needs and we could see how Haystack could update and improve the end user’s search experience. Core to its design is the ability it gives to developers to craft their own search to understand their own dialect. Its power stems from the wealth of research coming from the world’s best research teams and it allows users to express their informational needs through the most commonly used form of human communication: natural language.

