Knowledge Distillation with Haystack
14.04.22

Modern-day natural language processing (NLP) relies largely on big and powerful Transformer models. Language models like BERT have shown an almost human-like ability to process natural language. When fine-tuned to a question answering dataset, they are great at returning meaningful answers from large document collections.
But for some applications — for instance, deployment to mobile devices — the highest-performing models can be a bit too bulky. They are also slow to perform inference, which can become a problem if you want to scale your model to process hundreds or thousands of requests per day.
You might have heard about “knowledge distillation” and distilled models — smaller models that leverage the power of their larger counterparts while saving both time and resources. We’re happy to announce that the Haystack framework now provides all the tools needed to distill your own models in just a few lines of code. So if you’re looking to increase the performance of your models by making them faster or more accurate, this article is for you!
What is Model Distillation?
To determine the size of a model, you can look at its number of trainable parameters. This is the total number of weights in all the different layers of your model, and it is often in the millions or even billions. BERT-base, for example, has 110 million parameters, while BERT-large is three times that size. However, studies have shown that there is a lot of redundancy in deep learning models.
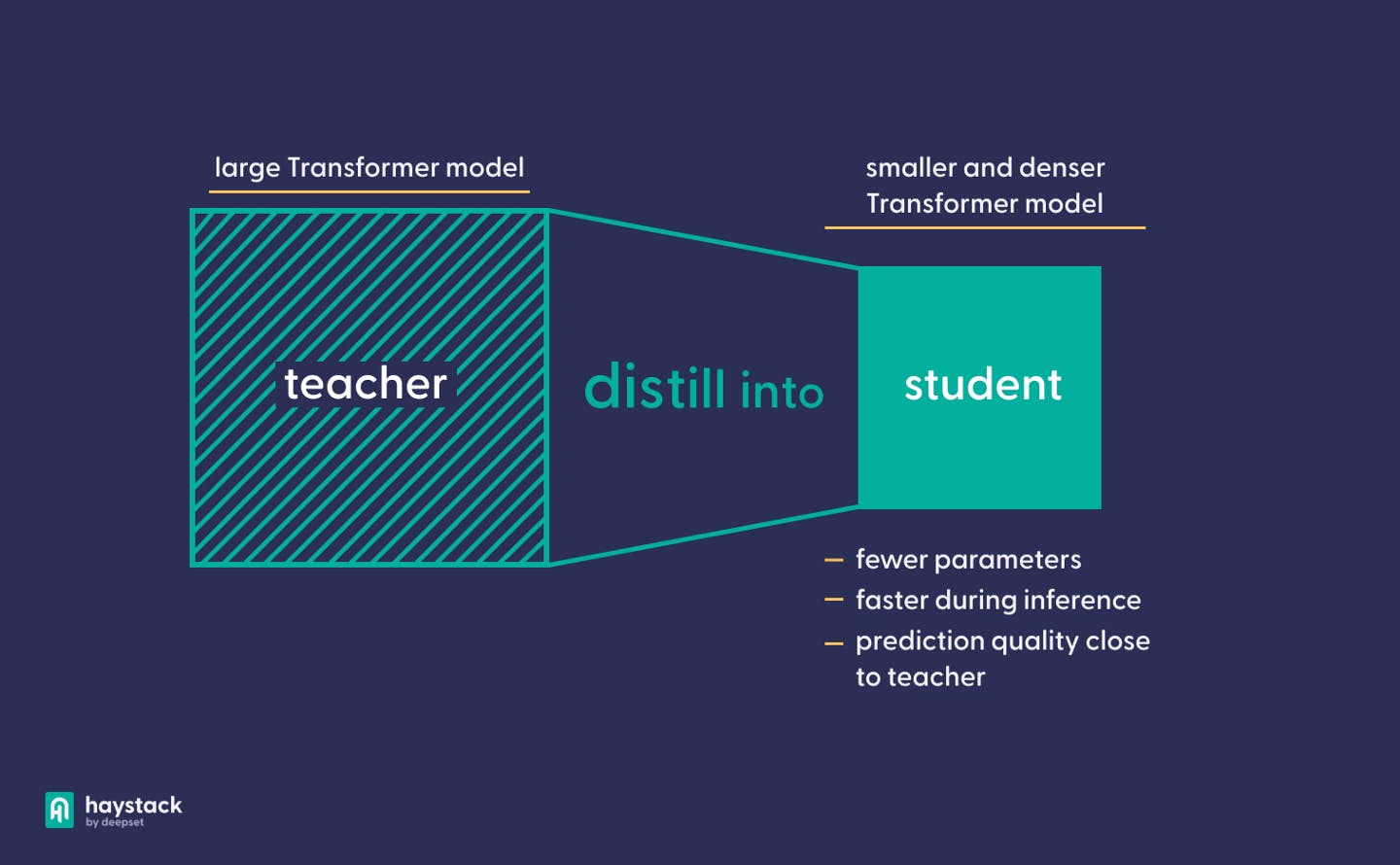
Model compression techniques seek to produce smaller models by eliminating that redundant information. Model distillation , a type of model compression, describes the transferral of knowledge from a large model to a smaller model with fewer parameters. A distilled model is much faster than the large model that it derives from. At the same time, it performs better than an undistilled model of the same size.
Why Would You Distill Your models?
There are at least two good reasons for distilling your models. It could be that you are happy with the quality of your model’s predictions, but want it to perform inference faster — perhaps to increase the number of queries that your system can process within a given time period. In that case, your model can be distilled into a smaller model. Depending on the distillation method, you can push the accuracy of your smaller model to be very close to that of the larger model.
Alternatively, you might want to improve the prediction quality of your model while retaining its size and inference speed. In that case, you could first train a larger model and then distill that model into your original, smaller model architecture.
As a rule of thumb, we recommend model distillation to anyone who wants to use a Transformer model in production. It lets you save memory, speed up inference, or increase the quality of your model’s predictions — what’s not to like?
How Does Model Distillation Work?
Model distillation works with a teacher-student paradigm. The “teacher” is a larger model whose knowledge we want to compress into a smaller, “student” model. To achieve that goal, we employ a range of loss functions that push the student to emulate the teacher’s behavior — either just in its prediction layer or in the hidden layers as well.
The process for distilling a model is similar to training a model from scratch: the model sees data and has to predict the right labels. For example, a question-answering model has to predict the correct answer span to a given question. Through a loss function, which measures how close its predictions are to the truth, the model learns to approximate the true distribution. In the context of model distillation, we use a combination of different loss functions, which serve to fit the new model not only to the data, but also to its teacher.
Unlike other compression techniques like pruning (which produces a smaller model by removing redundant weights), distillation is both model- and hardware-agnostic: it works out of the box for any kind of model architecture, and regardless of the underlying CPU or GPU hardware. However, as you’ll see, your choice of distillation technique might affect the teacher-student combination that you can use.
What Types of Model Distillation Are There?
There are two categories of model distillation. Prediction layer distillation is fast, only operates on the model’s output layer, and puts almost no constraints on the teacher-student combination. Intermediate layer distillation, on the other hand, takes much longer and involves several deeper layers of the model. Let’s look at both methods in more detail.
Prediction layer distillation
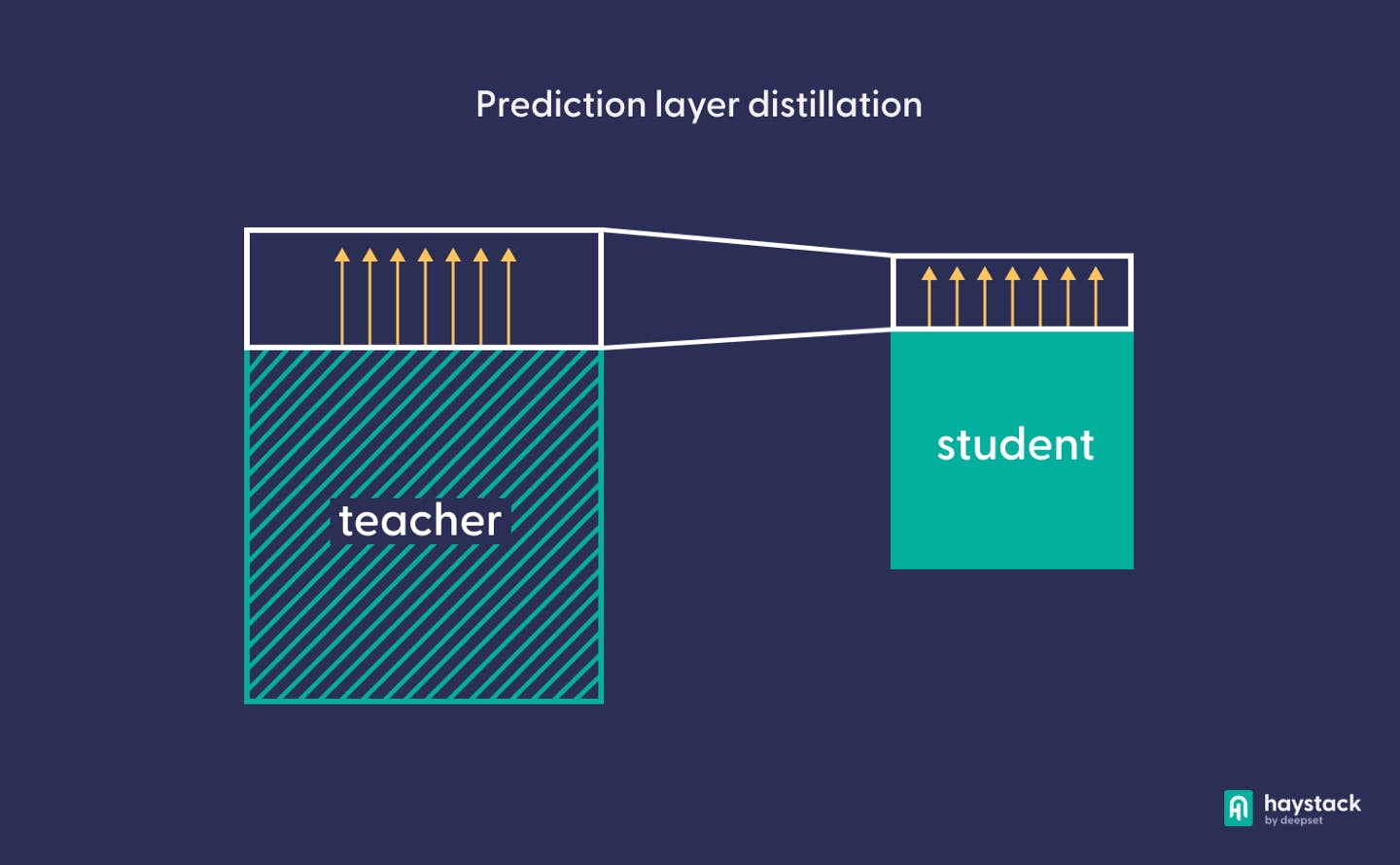
Originally proposed in 2015 by Hinton et al., this technique seeks to teach the student to approximate the teacher’s prediction layer outputs. It is based on the realization that in a deep learning model, knowledge about the domain is conveyed not only by the model’s top prediction but by the entire probability distribution over output labels. If a student model learns to approximate that distribution, it can successfully emulate the behavior of the teacher model.
Prediction layer distillation takes a couple of hours on a GPU, and there are two important hyper-parameters that regulate its behavior: temperature and distillation loss weight.
Temperature
To improve the expressiveness of the teacher’s output distribution, we want it to produce “soft” rather than “hard,” clear-cut predictions. When distilling the model, the softness of the predicted labels can be controlled through a hyperparameter known as temperature. A higher temperature results in a softer distribution.
Distillation loss weight
This parameter regulates how much the student model, during distillation, prioritizes the teacher’s output over the real targets in the training data. It ranges between 0 (use only the labels, ignore the teacher’s predictions) and 1 (learn only the teacher’s behavior, not the labels).
Intermediate layer distillation
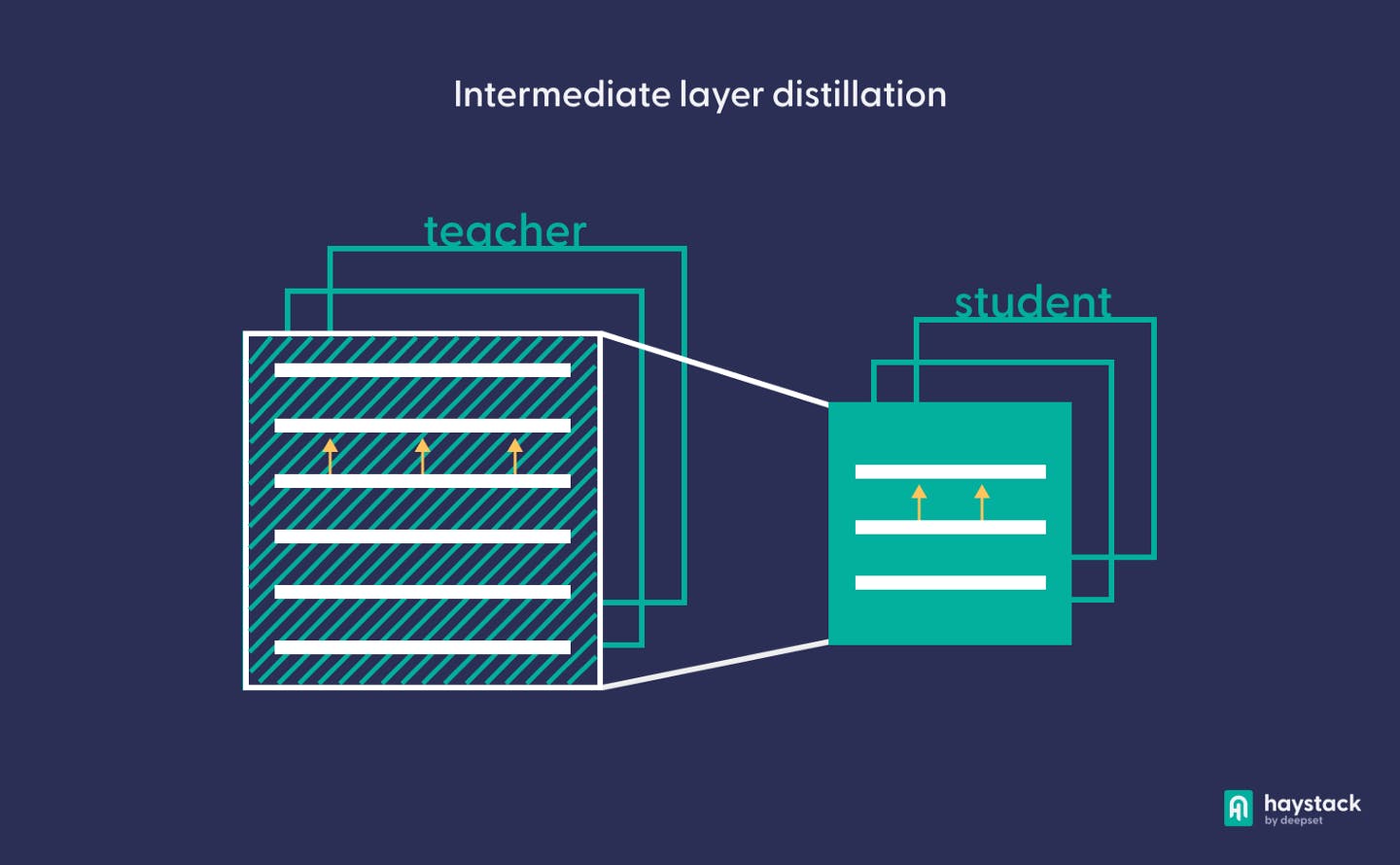
The main building blocks in Transformers are multi-head attention layers that learn to capture relationships between input tokens. In intermediate layer distillation, as proposed by Jiao et al., the student learns to approximate the teacher’s behavior with respect to not only the prediction layer but also the attention and embedding layers.
Because intermediate layer distillation involves the teacher’s hidden layers, it only works for teacher-student pairs that have similar architectures. For example, you can use BERT-base or BERT-large as teachers for a TinyBERT model.
In practice, this technique requires a two-step process. In the first step, the model is distilled using intermediate layer distillation. Since this step requires a lot of data, Haystack now provides the augment_squad() script. It lets you artificially augment your data by a given factor before performing the distillation. In the second step, we simply use prediction layer distillation, as before.
Our recommendation is to preface this two-step distillation of the fine-tuned model with an intermediate-layer distillation of the general language model. In that scenario, which has shown the best results in our experiments, your distillation procedure actually consists of three steps:
- Intermediate layer distillation of the general language model on a large text corpus (e.g. Wikipedia).
- Intermediate layer distillation of the fine-tuned, task-specific model, using the artificially augmented SQuAD dataset.
- Prediction layer distillation of the fine-tuned model, using the un-augmented SQuAD dataset.
This approach takes quite a long time — three to four days on four GPUs. But the investment pays off: your distilled model will take up less space and will process requests much faster than the teacher, with a higher accuracy than could be achieved with prediction layer distillation only.
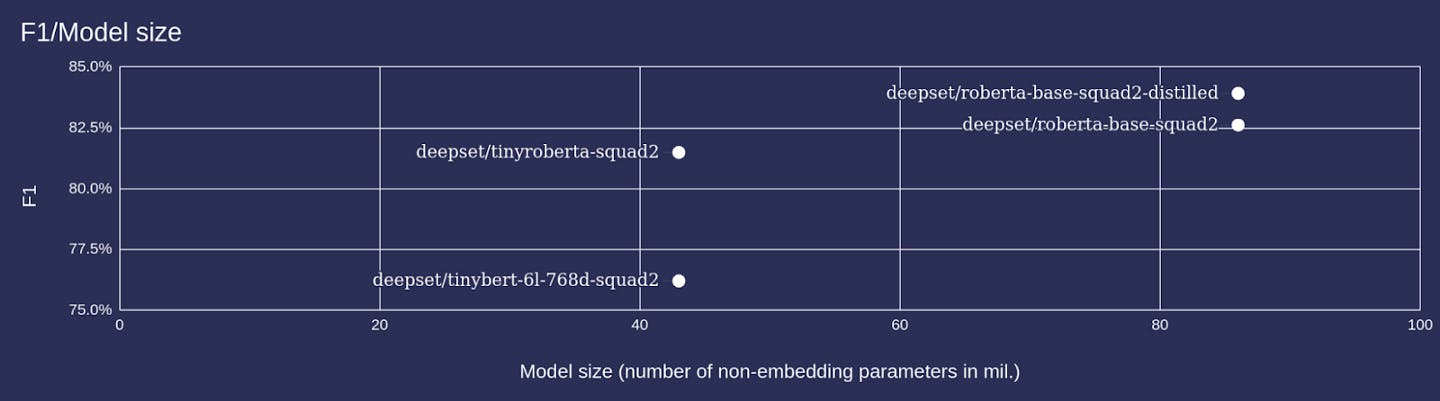
The following diagram shows the size of some models compared to their prediction quality as measured by the F1 score. The tinyroberta-squad2 model is roughly half the size of its teacher, roberta-base-squad2. Nonetheless, at 81.5, the student’s F1 score is almost as high as the teacher’s (82.6), and it is able to process requests at twice the speed of the larger model.
Plus, the distilled general-language model is reusable — it can serve as a basis for a number of downstream tasks. If you want to skip the first, computationally expensive step of distilling a general language model, you can even load our new deepset/tinyroberta-6l-768d model from the Hugging Face Model Hub. We trained it specifically for people with limited computing resources.
Get Started with Model Distillation
If you want to learn more about the two types of model distillation, have a look at our documentation page. The page also includes recommendations on the teacher-student combinations that you can use, optimal settings for the hyper-parameters, and some statistics on the improvement that you can expect to gain from distilling your models.
The code for both intermediate layer and prediction layer distillation is contained in this tutorial on model fine-tuning. The notebook exemplifies the relevant steps with a small toy dataset. Please note that since a real-world application of intermediate layer distillation takes several days on multiple GPUs, we don’t recommend running it in a Colab notebook.
If by now you’re convinced that model distillation is the way to go, but don’t have the time or resources to distill your own models, you can simply use deepset/tinyroberta-squad2 instead of its bulkier teacher.
Finally, if you haven’t already, come check out the Haystack repository on GitHub. And if you have more questions about model distillation or want to see what others are up to, make sure to join the Haystack community on Discord!

