BLOG
AI Best Practices
Product
Why Enterprise AI Costs Are Spiralling & How Sovereign AI Fixes the Economics
Enterprise AI costs are spiralling due to model mismatch, context bloat, agentic complexity, and weak governance. Learn why a sovereign AI approach is the key to controlling spend at scale.

Published on
June 2, 2026
12
min read
TLDR
Key Metrics:
Uber's CTO gave 5,000 engineers access to Claude Code in December 2025. By April, the company had burned through its entire 2026 AI coding budget.
Six weeks later, Microsoft began canceling most internal Claude Code licenses across its Experiences and Devices division (the group that builds Windows, Outlook, Teams, and Surface), directing engineers to switch tools by June 30.
These aren't cautionary tales from companies that got AI wrong. These are two of the most technically sophisticated organizations on the planet, and they got blindsided by the same thing: the changing economics of token-based AI at enterprise scale.
The challenge is no longer getting AI to work. It's making enterprise AI costs economically sustainable once it does. And the enterprises that are solving this problem share a common trait: they're building sovereign AI infrastructure that puts cost control in their own hands, rather than leaving it to their vendors.
Why Are Enterprise AI Costs Suddenly a Board-Level Concern?
For most of 2024 and early 2025, enterprise AI costs were deceptively manageable; vendors, backed by venture capital, subsidized access with generous free tiers and flat-rate seats, prioritizing adoption above all else. Nobody sweated the bill.
Two brutal, compounding shifts have since forced token-based economics directly onto the boardroom agenda.
The pricing model flipped. Vendors have moved aggressively toward consumption-based and token-based billing, passing volatile inference costs directly to customers. AI pricing now involves inconsistent metrics (tokens, credits, characters, "action units"), often using vendor-created currencies that make comparison across providers nearly impossible. One enterprise sourcing leader described it as comparing oranges to watermelons. Meanwhile, vendors frequently limit the price protections that used to be standard: multi-year term agreements, not-to-exceed clauses, and price caps are all harder to negotiate.
Agentic workflows blew up the math. A single user prompt to an autonomous agent can trigger chains of API calls, tool invocations, retrieval operations, and multi-step reasoning loops. Agentic pipelines routinely consume 10 to 50 times more tokens than a single-turn chat interaction. A workflow that cost pennies in a prototype can cost thousands in production. And because agents operate autonomously, there's often no human watching when AI agent costs spiral.
The Uber story makes the dynamic concrete. Claude Code adoption among their engineers jumped from 32% to 84% in a single month. Per-engineer costs ranged from $500 to $2,000 monthly. Around 70% of committed code was AI-generated. But when COO Andrew Macdonald talked to senior engineering leaders, he came away unconvinced that more spending was producing proportionally better results. His assessment on the Rapid Response podcast: "That link is not there yet. It's very hard to draw a line between one of those stats and, 'Okay, now we're actually producing 25% more useful consumer features.'"
The gap between adoption metrics that look like success and cost curves that look like a fire is the defining tension of enterprise AI in 2026. Over 40% of agentic AI projects are expected to be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls. And 90% of AI agents built before 2028 will likely need replatforming or rebuilding, making AI spend visibility and unit economics tracking not optional, but existential.
Token-based pricing is forcing every enterprise to confront the actual cost per AI request at scale. The question is whether they confront it by design or by invoice shock.
What Are the 5 Forces Driving Enterprise AI Costs?
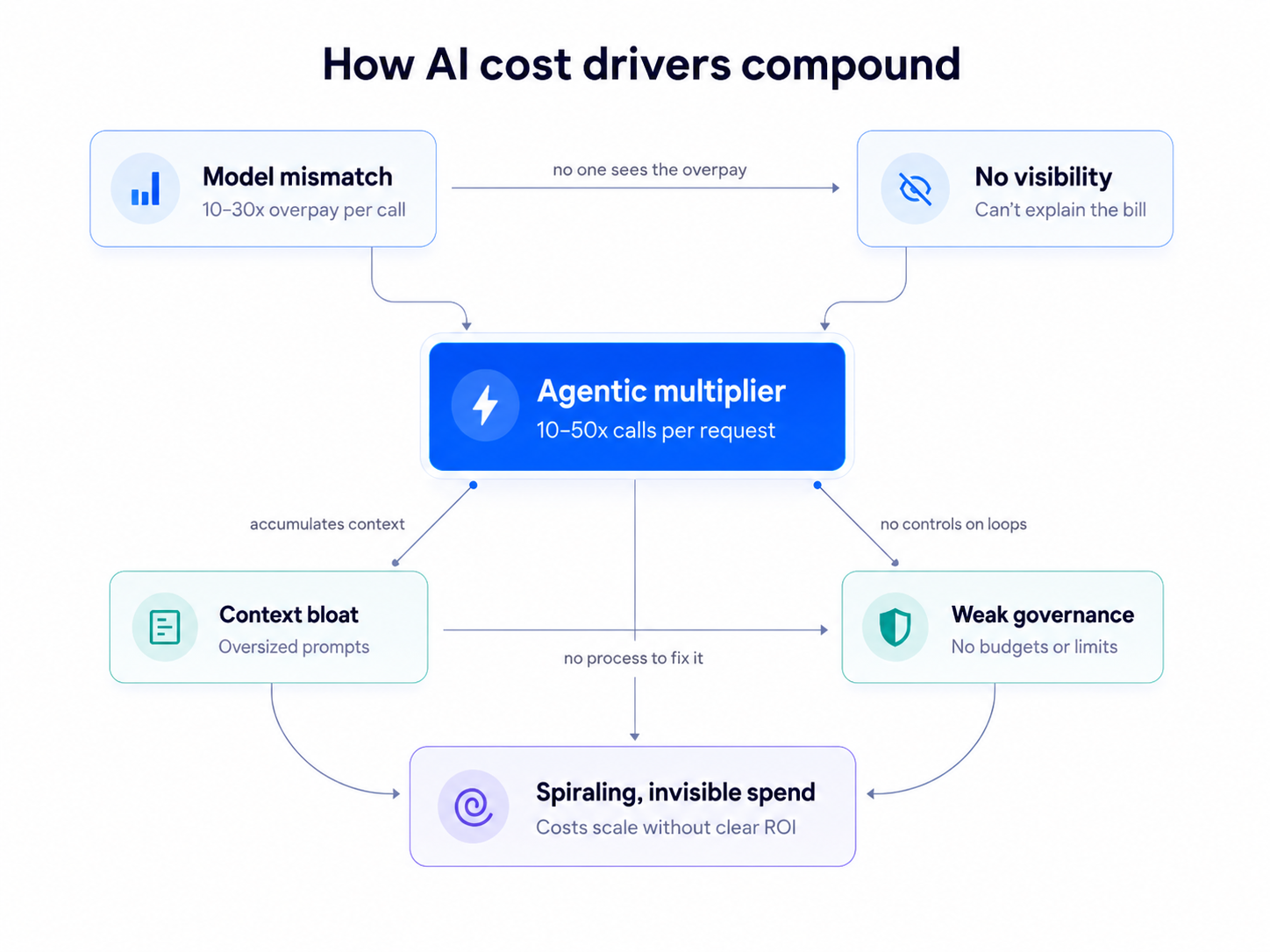
The AI cost management problem isn't one thing. It's a stack of compounding factors, and they reinforce each other in ways that make the total far worse than any individual line item suggests.
1. Model mismatch, paying frontier prices for routine tasks
There's a gravitational pull toward the biggest model in the room. Teams reach for the most capable option available (GPT 5.5 Pro, Claude Opus 4.8, Gemini 3.5) for every task, including summarization, classification, routing, extraction, generation, regardless of whether that level of intelligence is needed.
But many enterprise AI tasks are straightforward: classifying support tickets, extracting fields from invoices, routing requests to the right team, summarizing short messages, matching questions to knowledge base articles. These can often be handled by smaller models, cheaper models, open-source alternatives, embeddings, rules, or even traditional software logic.
The LLM cost optimization opportunity here is significant. A frontier model can cost 10-30x more per token than a mid-tier alternative. A slight overpayment on a single request may seem trivial, but when that request pattern runs hundreds of thousands of times per month, the impact compounds quickly.
Put simply: many companies are using PhD-level models for intern-level tasks.
2. No visibility into AI spend
Many enterprises can see their overall AI bill, but they can't explain it. They know their spend is increasing, but they don't know which products, teams, agents, customers, prompts, or workflows are responsible.
This creates a dangerous gap between usage and accountability. Without proper LLM observability, teams may not know how many model calls happen behind a single user request, which agents or workflows are generating the most spend, how much cost comes from input tokens versus output tokens, how much is caused by retries, failures, or long prompts, or whether expensive outputs are actually producing business value.
This is especially problematic with AI agents. What looks like a single user interaction may involve a long sequence of internal model calls, retrieval steps, tool calls, retries, and evaluations. The enterprise knows AI is expensive, but not why.
3. Agentic systems multiply calls behind the scenes
Traditional software has relatively predictable execution paths. A user clicks a button, a service runs, a database is queried, a result is returned.
Agentic AI systems behave differently. An AI agent may need to reason, plan, retrieve information, call tools, interpret results, critique its own work, retry failed steps, and generate a final answer. A single user request can trigger a cascade of hidden operations.
Consider a concrete example: one request to an enterprise research agent might involve understanding the user's intent, creating a plan, searching internal documents, calling external tools, reading retrieved content, summarizing intermediate findings, checking for missing information, running additional searches, comparing sources, and producing a final response. That's ten or more model calls for what the user experiences as one answer.
The challenge becomes more complex with multi-agent systems, planner-executor patterns, reflection loops, and autonomous retries. These designs can improve quality, but they multiply AI agent costs dramatically if left unchecked.
In other words: agents turn one user request into a hidden chain of expensive reasoning and tool use.
4. Context bloat drives up token consumption
AI costs aren't only driven by the number of calls. They're also driven by the amount of context sent into each call.
In many enterprise systems, prompts become heavier over time. Teams add more instructions, more examples, more policies, more documents, more metadata, and more conversation history. Each addition may be individually reasonable, but together they create bloated prompts that are expensive to run.
This is where retrieval-augmented generation, done well, becomes a cost lever rather than a cost driver. A well-tuned RAG pipeline narrows a large document pool down to only the passages the model actually needs, replacing brute-force context stuffing with precise, targeted retrieval. The difference is significant: feeding the model 3 relevant passages instead of 20 marginally related ones can cut token consumption for that call by 80% or more, with no loss in output quality.
Common sources of context bloat include long system prompts, full conversation histories passed on every turn, large retrieved document chunks, irrelevant RAG results included "just in case," verbose tool outputs, repeated instructions, oversized JSON schemas, growing memory stores, and excessive customer or account metadata.
Instead of sending only the most relevant context, systems send too many chunks, oversized passages, or partially relevant documents as a safety margin. Agentic workflows compound the problem: each step passes forward previous reasoning, tool outputs, intermediate summaries, and state. Over multiple steps, token usage snowballs.
The result: companies pay models to re-read oversized context again and again, on every single call.
5. Cost governance has not kept up with AI adoption
Most enterprises did not start their AI journey with mature financial controls. They started with experimentation. Teams were encouraged to prototype, test, and move quickly. That made sense in the early stages.
But many of those prototypes have now become production workflows. Usage has grown, more teams are building with AI, more customers are interacting with AI-powered features. Yet the operating model for controlling spend often remains immature.
Common governance gaps include:
- No clear budget ownership by team, product, agent, or customer
- No model selection policy
- No spend limits or alerts
- No approval process for high-cost workflows
- No cost-per-task targets. No chargeback or showback model
- No evaluation of cost versus quality
- No process for retiring inefficient prototypes
When nobody owns the economics of an AI workflow, costs naturally rise. Teams optimize for capability, speed, and user experience, but not efficiency. This isn't carelessness, but instead a sign that the organization hasn't yet built the financial and operational muscle required to manage AI cost governance at scale.
AI adoption has scaled faster than AI cost governance. And this gap leads directly to escalating, unmanaged spend and a lack of budget control.
Why does the combination matter more than any single force?
Each of these issues is costly on its own, but the real damage happens when they stack.
An enterprise might use a premium model inside an agentic workflow. That workflow makes many hidden calls. Each call includes bloated context. The team lacks AI spend visibility into which step is expensive. And there's no governance process to set limits or require a cheaper alternative.
That is how enterprise AI costs get out of control. The problem is not just model pricing. It's the interaction of model mismatch, lack of observability, agentic call multiplication, context bloat, and weak cost governance. Together, these forces create an environment where AI spend scales quickly, invisibly, and often without a clear connection to business value.
Why Sovereign AI Is the Cost Control Strategy Enterprises Are Missing
If the five forces above describe how enterprise AI costs spiral, then sovereign AI describes the structural condition that makes those forces controllable.
Sovereign AI is the principle that an organization maintains independent control over its AI systems, data, models, and infrastructure. Sovereign AI has been discussed in the context of national security, regulatory compliance, and data privacy. These motivations remain critical: data residency requirements, protection from foreign jurisdiction (such as the U.S. CLOUD Act), GDPR and HIPAA compliance, and the need for full auditability all drive enterprises and governments toward sovereign architectures.
But there is a less discussed and equally urgent reason to pursue sovereign AI: cost sovereignty is a prerequisite for cost control.
Consider why the five forces are so hard to address when your AI stack is built on opaque, vendor-managed services. You can't route queries to cheaper models if you don't control the orchestration layer. You can't optimize context if you can't inspect and modify the retrieval pipeline. You can't attribute costs to specific workflows if the vendor's platform treats your usage as a black box. You can't enforce governance policies programmatically if the execution environment isn't yours. And you can't switch providers when pricing shifts if your entire system is locked into a single vendor's API.
Every lever of cost control: model routing, context engineering, observability, governance, provider flexibility, depends on one thing: owning the infrastructure layer where those decisions are made.
This is the link between sovereign AI and sustainable economics. Sovereignty isn't just about where your data lives. It's about whether you have the architectural authority to optimize how every token is spent, which model processes it, how much context accompanies it, and whether the result justified the cost.
The organizations that treat AI infrastructure as something they rent from a vendor will always be price takers. The organizations that build or adopt sovereign AI infrastructure become price makers, who are able to swap models when a cheaper alternative emerges, tighten retrieval when costs spike, enforce budget limits programmatically, and maintain full visibility into what every AI request actually costs.
As Gartner has recommended, sovereign organizations should implement model-agnostic workflows using open standards and orchestration layers. This isn't just a compliance strategy, it's an economic one. Vendor lock-in is a cost multiplier. Sovereignty is a cost lever.
How Can Teams Solve the Enterprise AI Cost Problem?
AI cost management is not a procurement problem. It's an architecture, observability, and governance problem - and solving it requires sovereign control over your AI stack. Negotiating better model pricing helps, but it won't fix the five forces above. Instead AI teams need to gain systematic control over five levers:
- Optimizing context so fewer tokens reach the model
- Routing requests to right-sized models
- Swapping providers without rewriting code
- Building architecture for end-to-end AI spend visibility
- Unifying infrastructure so the full pipeline can be optimized as a single system
These levers share a common dependency: the organization needs to control its own orchestration and deployment layer. This requires an infrastructure layer for retrieval, routing, generation, and evaluation that operates independently of any single model vendor or SaaS provider. When that layer is under the organization's control, AI cost management becomes a systematic engineering discipline rather than a reactive budget exercise.
The core insight is that context engineering is cost engineering. The cheapest token is the one you never use. Every improvement in retrieval precision, every reduction in redundant context, every intelligent routing decision translates directly into lower LLM token costs. It's the architectural equivalent of energy efficiency: invisible when done well, devastating when neglected. This compounds: better retrieval reduces the cost per AI request on every future call, across every model, every provider, every pricing change.
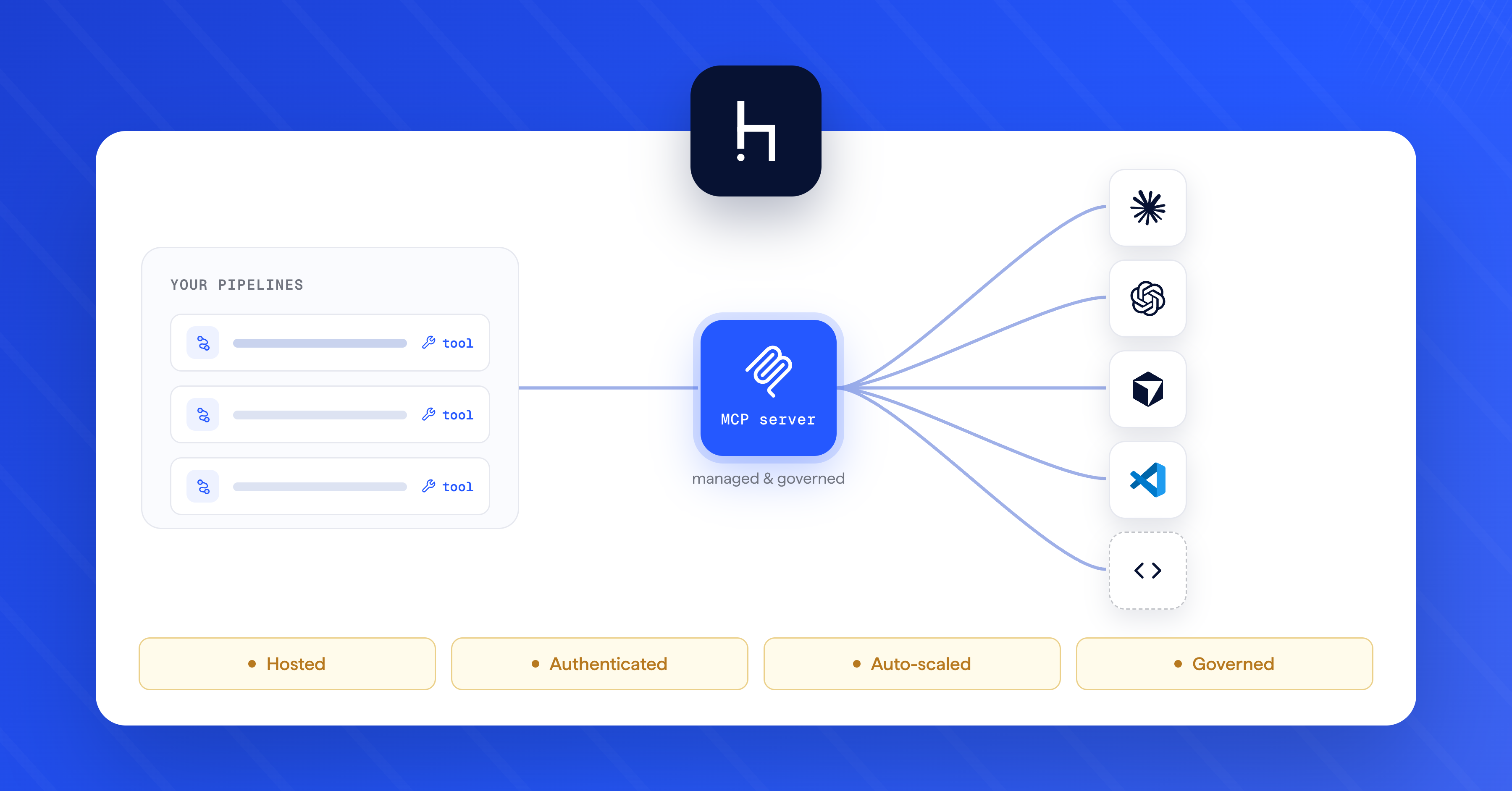
The Haystack Enterprise Platform, built on the foundation of the open-source Haystack framework, is designed to give organizations this level of control. The open-source core provides the battle-tested building blocks: retrieval, ranking, filtering, routing, tool use, memory, and generation components that thousands of developers build with daily. The enterprise platform adds what teams who deploy and manage agentic AI systems to production on top: version-controlled pipeline management across teams, evaluation workflows, deployment across cloud, on-prem, or hybrid environments, and the governance controls that turn experiments into sustainable systems.
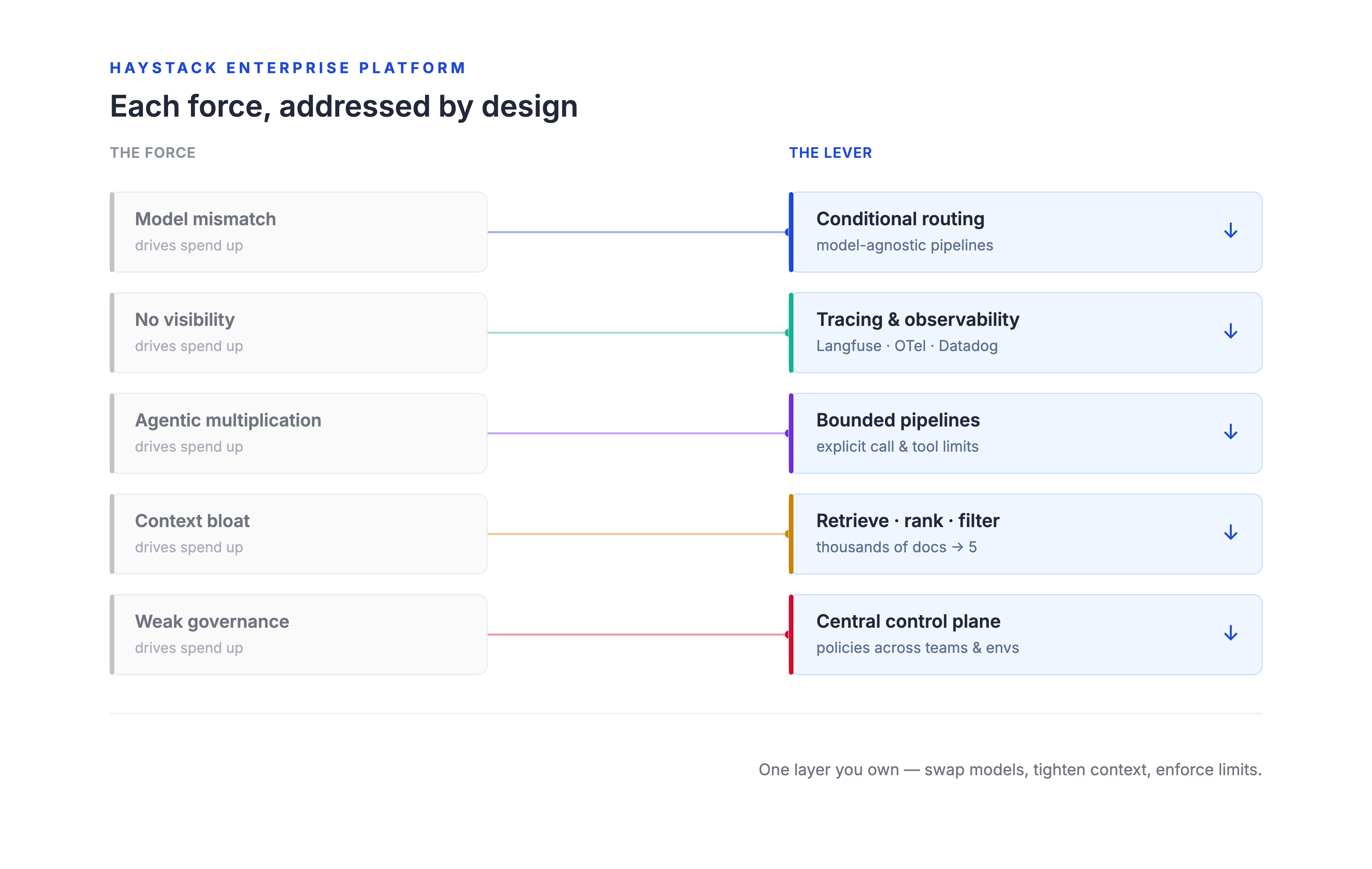
Here's how the Haystack Enterprise Platform addresses each of the five cost forces:
Model mismatch: conditional routing and model-agnostic pipelines. The platform integrates with OpenAI, Anthropic, Mistral, Cohere, Hugging Face, Azure, AWS Bedrock, local models, and others. Teams build pipelines once and route queries to different models based on complexity, cost, or policy. A simple factual lookup hits a lightweight open source model. A complex reasoning task hits the latest frontier model. When a vendor raises prices or a new model drops that's 3x cheaper for your use case, you swap at the platform level, not in application code. Evaluate the new model on Monday, benchmark it on Tuesday, route production traffic on Wednesday. This is what model sovereignty looks like in practice: the model is a pluggable component, not the foundation. No vendor lock-in means no cost lock-in.
Poor visibility: tracing and observability built in. The platform supports native integrations with Langfuse, Weights & Biases Weave, MLflow, OpenTelemetry, and Datadog. See token usage, latency, and cost at every pipeline step. Identify which components are burning tokens, which retrieval strategies are most efficient, and where optimization effort will have the highest return. This provides the full telemetry flowing into the monitoring tools you already use.
Agentic cost multiplication: pipeline-first governance. Agent workflows on the platform are explicit, traceable, and bounded. Deterministic orchestration with iteration limits, explicit tool access, approval checkpoints, and fallback logic gives enterprises a governed execution layer. With our Agent component and related components, teams can set explicit limits on the number of LLM calls and tool invocations an agent is allowed to make, helping prevent runaway costs. Agents scale within predictable cost envelopes rather than spiraling through unbounded loops. The pipeline architecture means every step is auditable, and cost attribution is structural rather than guesswork.
Context bloat: retrieval pipelines that cut tokens at the source. The platform's retrieval, ranking, and filtering components narrow large document pools down to only the information the model needs. Start with thousands of documents; feed the LLM five. Reranking surfaces the most relevant content first. Filtering eliminates noise before it reaches the model. Fewer documents in the context window means a cheaper bill, regardless of which provider you use or how they change their pricing.
Weak governance: centralized control across teams and environments. The enterprise platform provides a single control plane where teams manage pipelines, enforce model selection policies, run evaluations to compare pipeline configurations, and deploy consistently across cloud, on-prem, or hybrid environments. This is what turns AI cost governance from a policy aspiration into an operational reality. Sovereign deployment flexibility allows the choice of where and how to run AI workloads, making it a direct cost lever that adapts to the varying economics of different deployment targets.
The practical workflow this enables is powerful: try out different models quickly and compare consumption. Run evaluation scripts to compare pipeline configurations. Get fast end-user feedback. Iterate toward cost efficiency with data, not guesswork.
Using the Haystack Enterprise Platform enables teams to stay independent of any single model vendor. Your pipelines, your retrieval logic, your routing rules, your governance controls, all of it stays intact. The model is a pluggable component, not the foundation. This gives the enterprise genuine negotiating leverage in a market where vendor pricing is still volatile and immature.
What Should AI Teams Do Now?
The enterprises that will sustain AI beyond 2027 are the ones building cost discipline into their architecture today, not the ones hoping prices will drop fast enough to bail them out. Three actions matter most:
Make every pipeline's cost legible from day one. Before anything goes to production, wire in the monitoring that lets you see what each request actually costs: which components consume the most tokens, where latency spikes, and whether the output quality justifies the spend. If the team shipping a pipeline can't produce a cost-per-task number on demand, the pipeline isn't ready.
Build the guardrails into the system, not the policy document. Spending limits, automatic model downgrading when budgets run hot, caching layers that prevent redundant calls, and hard stops that require a human sign-off before expensive operations fire. Controls that exist only in a governance slide deck won't survive contact with a production agent that decides to call an API 400 times in a loop.
Prove the economics before you scale. Every AI use case should have a clear cost-per-outcome curve, tested at realistic volumes, before it gets promoted beyond a pilot. A pipeline that looks efficient at 100 requests per day can hemorrhage money at 100,000. If the unit economics don't hold up under load, adding more traffic just accelerates the loss.
The Bottom Line: Cost Control Requires Sovereign Control
The AI cost crisis is not a reason to slow down on AI. It's a reason to get serious about how AI systems are built.
The first generation of enterprise AI proved that the technology works. The next generation will be defined by something smarter: making it controllable, governable, and economically sustainable at scale. The organizations that treat orchestration, context engineering, and AI cost governance as core architectural concerns, not problems to solve after launch, will be the ones still running AI in production three years from now.
This is ultimately a question of sovereignty. Organizations that own their orchestration layer can swap models when pricing shifts, tighten context when costs spike, route intelligently across providers, and enforce governance programmatically across every team and workflow. Organizations that don't own that layer absorb whatever costs, constraints, and pricing changes their vendors impose. This is the true danger of vendor lock-in.
Sovereign AI has always been about control - control over data, compliance, security, and governance. What the cost crisis reveals is that economic control belongs on that same list. The future of enterprise AI is not just about better models. It's about sovereign infrastructure that gives the organization the optionality to optimize continuously, the visibility to know what's working, and the independence to adapt as the market evolves.
That's the layer where lasting advantage gets built, and where the bill finally starts making sense.
{{cta-light}}
Curious about building AI Apps and Agents?
Table of Contents