Labeling Data with the Haystack Annotation Tool
Here's how Haystack free annotation tool can help to create question answering datasets.
23.09.21

Note: The hosted annotation tool has been been deprecated. You have the option of self-hosting instead.
If you’re interested in natural language processing (NLP), then you are probably aware of the importance of high-quality labeled datasets to any machine learning model.
Without annotated datasets, there would be no supervised ML. This is especially true for Transformer-based neural networks, which are particularly apt for solving natural language tasks — be it question answering (QA), sentiment analysis, automated summarization, machine translation, or text classification. Supervised models depend on labeled data for both training and evaluation. But creating high-quality datasets from scratch is a tedious and expensive process.
Haystack provides a free annotation tool to assist you in creating your own question answering (QA) datasets, making the process quicker and easier. Read on to learn more about Haystack annotation tool and how to use it.
What is Data Labeling?
Data labeling (or ‘annotation) is one of the tasks necessary when developing and maintaining a machine learning model. It involves identification of raw data, e.g., images, videos, text documents, and assigning labels to that data so that the machine learning model can properly interpret the context, learn from it and make accurate prediction during the inference process.
For example, labels might ‘tell’ whether an image contains a dog or train, which words an audio recording consists of, or if a text file contains answers to a specific question.
Data labeling is needed for many use cases where machine learning is involved, such as computer vision, speech recognition, or natural language processing.
Annotating Natural Language
Annotation sounds like an easy enough task: simply assign a label to a sentence, paragraph, or document. But anyone who has annotated would say otherwise. Real-world complexities often prevent neat categorization into discrete labels. When annotating, you’ll struggle through cases where multiple labels might fit an example — or none at all. Clear and comprehensive annotation guidelines facilitate the annotator’s job.
In the context of question answering, labels are swapped for answer spans. Of course, that increases the complexity of the annotation task. While it’s relatively easy to add labels to documents, annotating large answer spans is a more involved process.
We’ve designed the Haystack annotation tool to assist you in your annotation process. It’s free to use and allows you to seamlessly coordinate work between team members. Simply upload your documents, add questions, and mark your answer spans. Done! Your dataset is then ready to be exported in the SQuAD format, which can be used directly to fine-tune or evaluate a question answering model.
Create Your Own Datasets
With so many curated datasets out there, why should you still annotate your own data? That’s because any machine learning model is only as good as the data it’s trained on. And if your question answering model is specific to a certain use case — say, financial statements or legal documents — you’ll be hard-pressed to find datasets that perfectly suit your needs.
The good news is that you can employ a technique called “domain adaptation”: You take a model that’s been pre-trained on a large general QA dataset like SQuAD (the standard dataset for question answering) and fine-tune it with your own data. The amount of data needed for fine-tuning is, thankfully, much smaller than the data required to train a model from scratch.
Apart from training, customized datasets are also useful for evaluating your systems. How can you tell whether your QA pipeline will properly cover your customers’ questions if you’re only evaluating it on an off-the-shelf dataset? To best measure your system’s performance for your use case, you’ll need a dataset that resembles your real-world data as closely as possible.
The Haystack Annotation Tool
Note: The hosted annotation tool has been been deprecated. You have the option of self-hosting instead.
You can use Haystack’s annotation tool locally via Docker. As an admin, you can set up projects, upload documents, and invite team members. The tool helps you coordinate your team’s work by setting up standard questions and assigning members sets of documents. Want to see the tool in action? Let’s take a closer look!
Using the Annotation Tool: A Walkthrough Example
Once you’ve logged in, create a new project by clicking on the “Create Project” button. Then, go to the “Import” dropdown menu and select “Documents” to upload your files. The files should be in plain .txt format and contain nothing but the text. For our example, we’ve imported a couple of cleaned Wikipedia articles about various West African dishes.
Once you’ve uploaded your texts, you can see them under “Documents”:
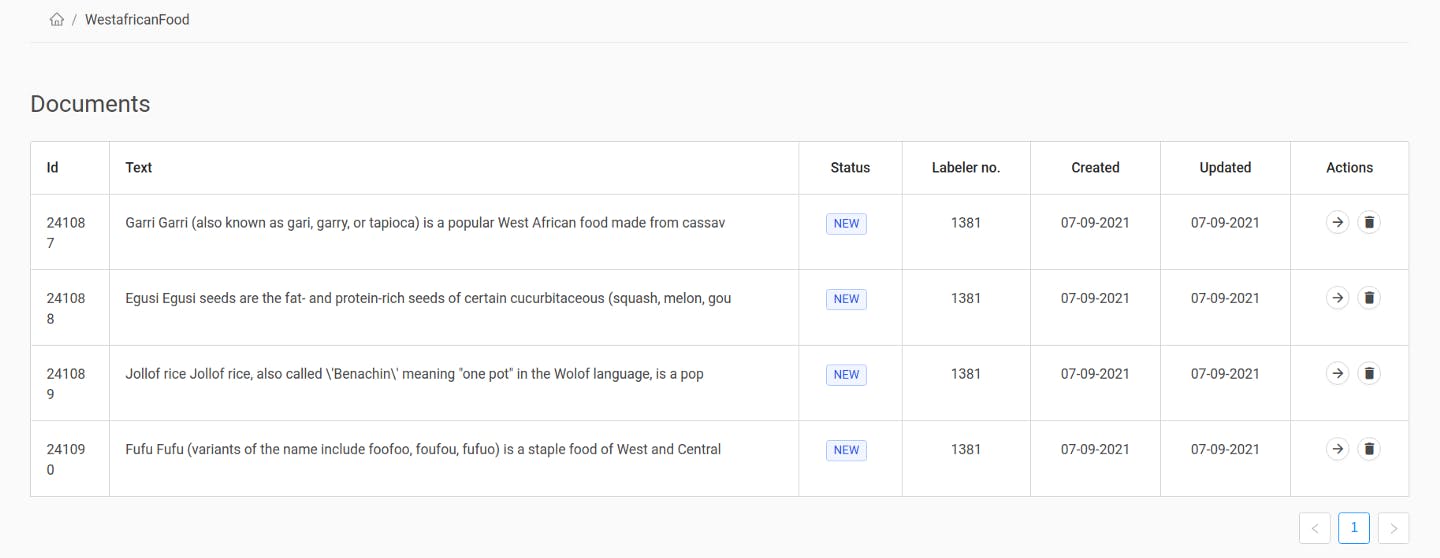
To change to document view, click on the arrow next to a document. You’ll see the entire text and a “Questions” menu. Now we can finally create question-answer pairs! Let’s look at the concept of unique questions first, before we move on to standard questions.
Unique Questions
To add a unique question, we follow a somewhat reversed process: After clicking the “Add Custom Question” button, we’ll use the cursor to mark a text span. This will open a small window where we can type in the question matching that answer span:
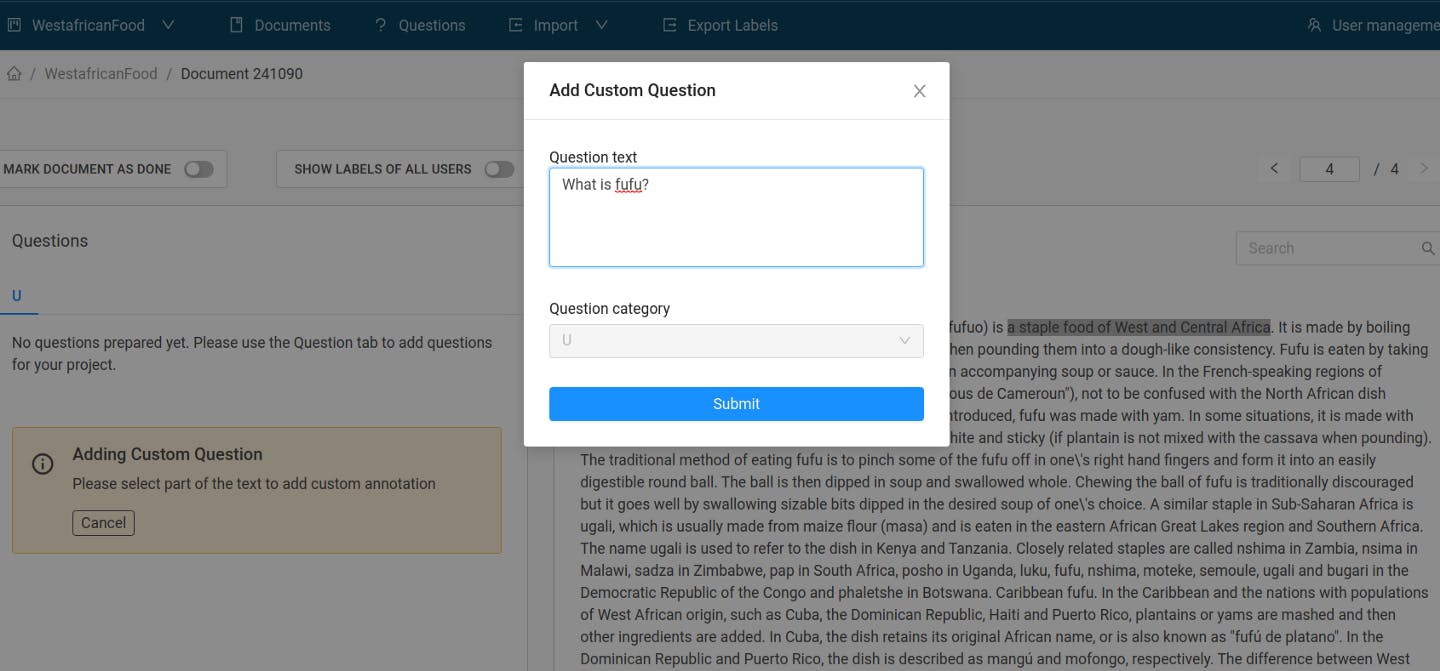
After going through this process a few times, we end up with an organized display of our question answer pairs.
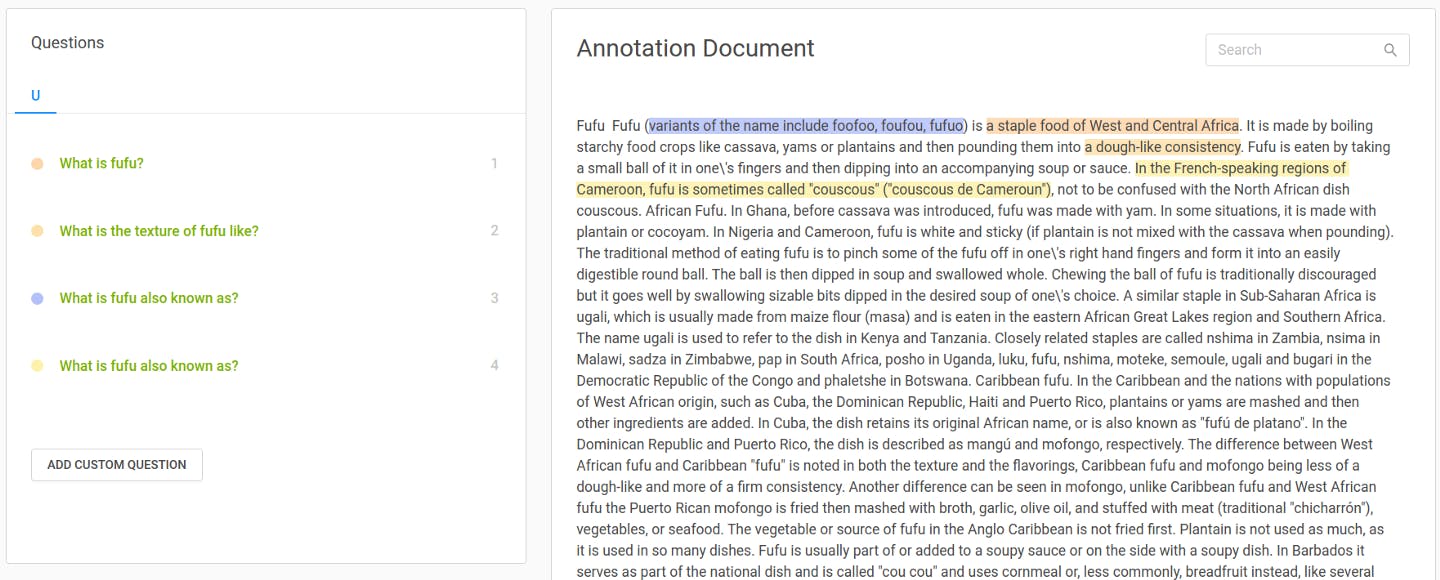
The questions are filed under “U” for “unique,” meaning that the annotator came up with them on the spot. But this is just one method of annotating question-answer pairs; the other one is provided by standard questions.
Standard Questions
If the documents in your database all resemble each other — maybe it’s a collection of patent documents, or your company’s earnings reports — you’ll probably want to answer the same questions in every document. Working with unique questions would be inefficient in that case.
Instead, you can set up a “standard questions” block where you can define questions in advance. The annotator then simply has to find the right answers in all the documents assigned to them.
In our example project, we’ve created two standard questions and assigned them to a new block (“G” for general):
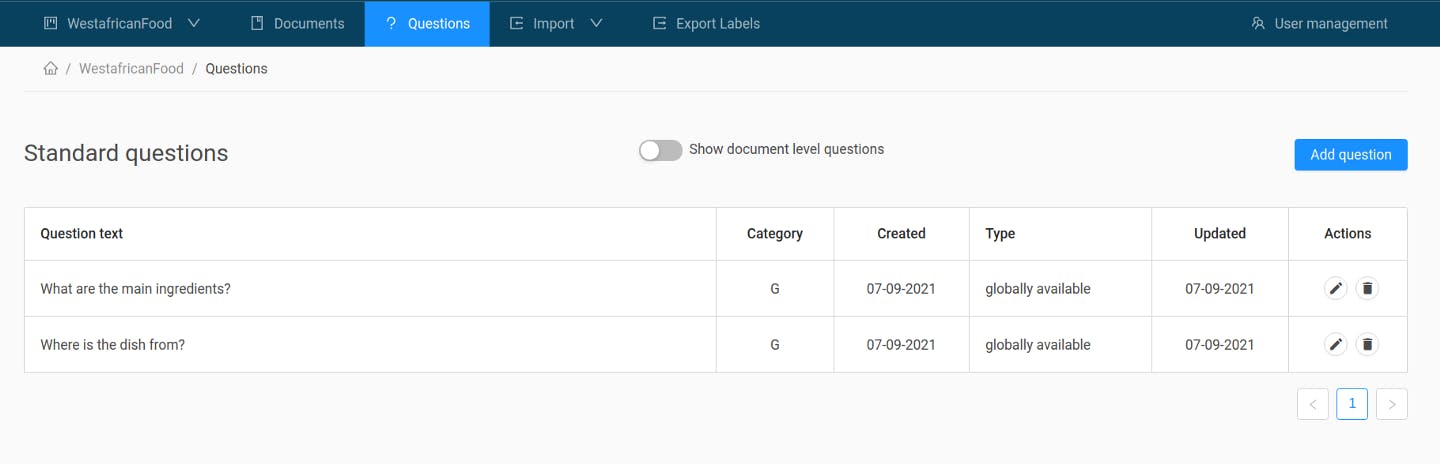
Going back to our document view, we see that we now have two question blocks: G and U. To answer the ready-made questions from a block, we click on the question and mark the appropriate answer span:
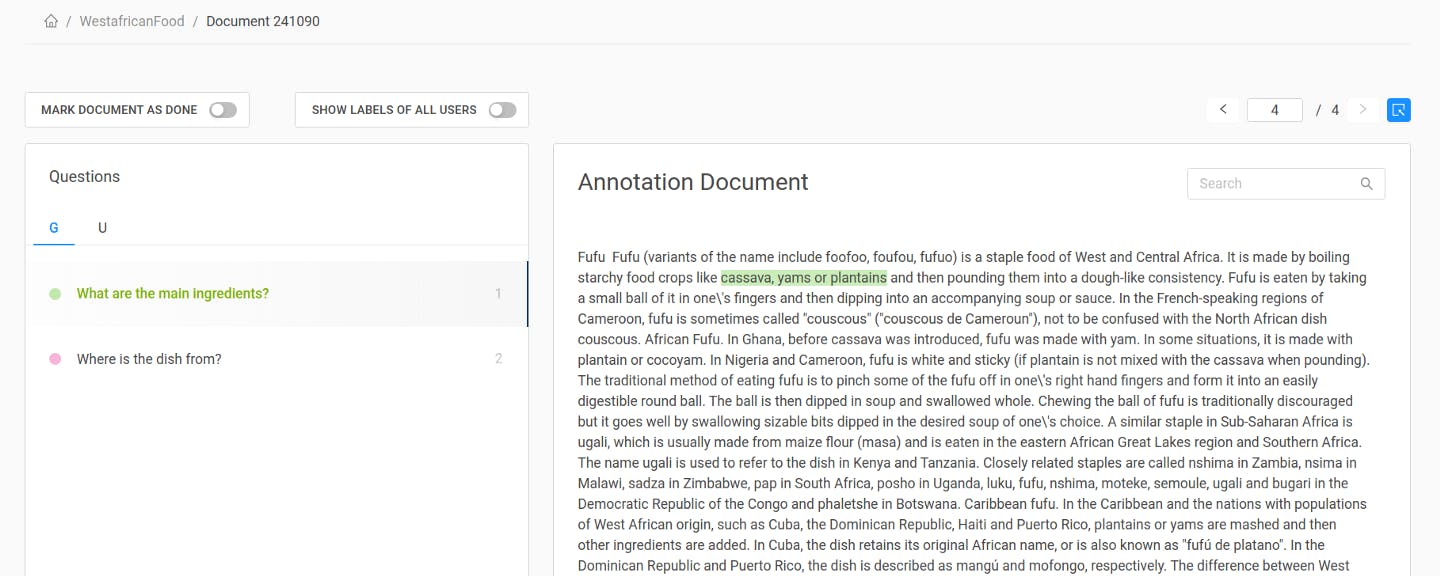
With standard questions, you can create more robust datasets. A diverse set of answers allows you to train the accompanying questions to maximum performance and evaluate them on distinct documents.
For your team, consider setting up projects that contain batches of similar documents with an associated standard questions block. Additionally, every project has a unique questions block by default. Annotators can use it if they can’t find their question under standard questions, or if they want to have multiple labels to answer the same question.
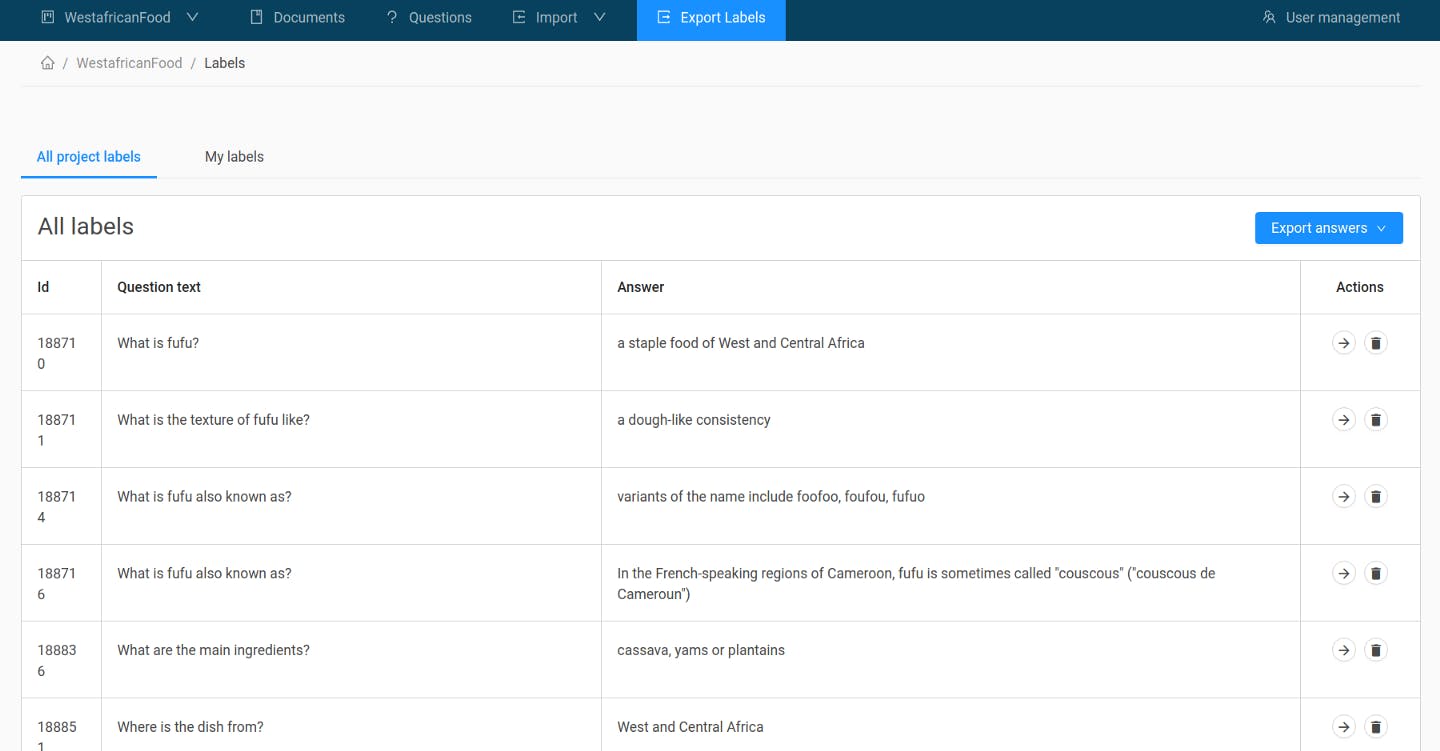
Exporting the Annotated Dataset
To use your new dataset to train and evaluate your systems, it needs to come in a SQuAD format, with questions and their answer spans stored in a JSON file. You can easily export your annotated data to that format. Simply go to “Export Labels” and click the “Export Answers” button. You can then choose between a CSV and a SQuAD JSON format.
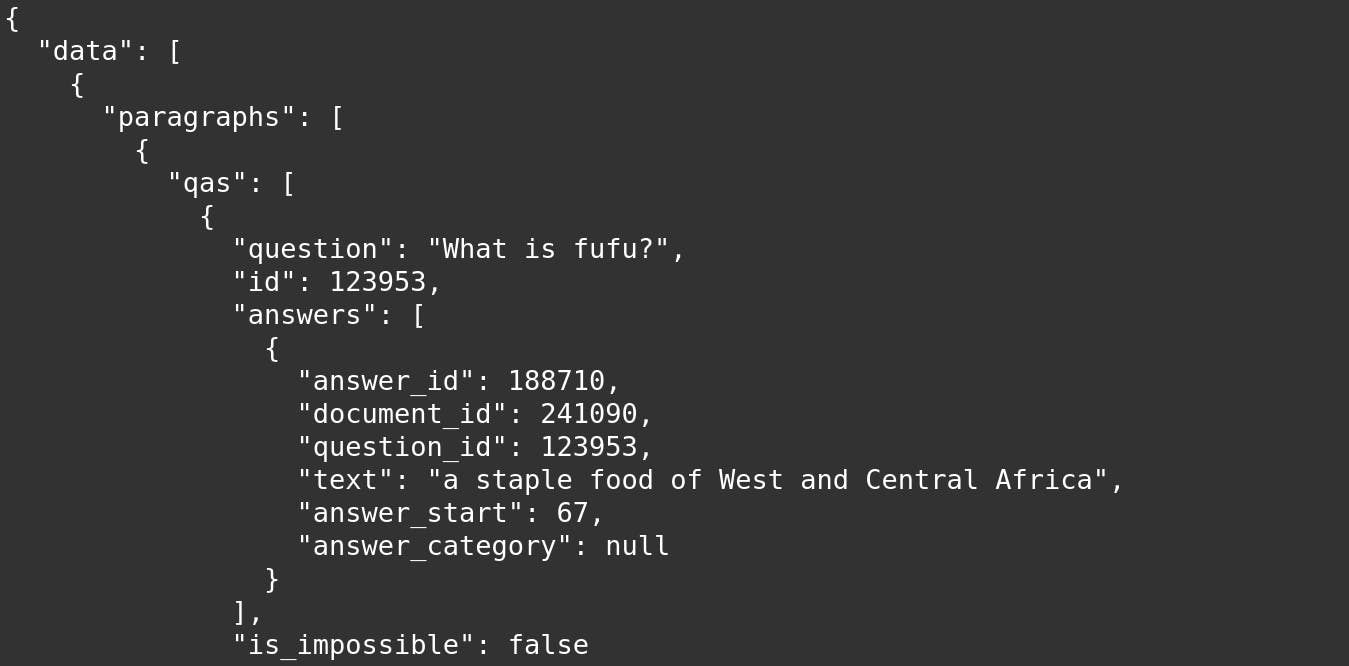
Here’s an example of an exported JSON file:
Designing Your Questions and Answers
So how might you come up with adequate questions and answers? Here are some quick tips adapted from our guide to question-answer pairs:
Questions
As a general rule, design your questions as you would phrase them in natural language. Don’t try to make them fit the answers by using the same words or order of words contained in the text. On the contrary, you’re better off using synonyms and changing the word order in your question, which provides more lexical and syntactic variety for the model to learn from. For example, in our document about fufu, we asked “What is the texture of fufu like?” and marked the answer “a dough-like consistency.”
A good question is fact-seeking, aiming to fill a gap in the inquirer’s knowledge. It should be answerable by the document at hand, and neither the question nor answer should require additional context to understand them. A question like “How authentic is fufu from the Buka restaurant?” isn’t a good choice because it is subjective and depends on external knowledge.
Polar questions (“yes-no questions”) are possible, but they shouldn’t make up more than 20 percent of the entire dataset. Note that the answer will still be a passage extracted from the text rather than “yes” or “no.” For example, a possible answer to the question “Do you eat fufu with your hands?” could be “Fufu is eaten by taking a small ball of it in one’s fingers.”
Answers
Question answering models prefer shorter answers to longer ones: That’s why, for our first question “What is fufu?”, we marked “a staple food of West and Central Africa” as the appropriate answer, rather than the entire containing sentence.
Answer spans can overlap or be identical, but each question can only be paired with one answer. If your question has more than one answer candidate in a text, you can ask the same question repeatedly. The same is true for standard questions — if a document has more than one answer candidate, simply create a unique question using the same wording.
Use Your Own Datasets to Build a Tailored Question Answering Pipeline
With your data sets annotated, you might look to train a question answering system. The Haystack framework offers all the tools you need to set up a QA pipeline. Check out our GitHub repository — and if you like what you can build with it, we’d appreciate a star from you :)

