Why Does a Trained Question Answering Model Need Data?
Have you ever wondered if extractive QA models contain answers? Read on to learn more!
18.05.22

When people approach natural language processing, and specifically question answering, for the first time, there are a few concepts that cause confusion around models, training them, and the need for data: Will I need to train a model on my own data? Where do the answers come from? And so on.. I’ll try to address some of these and shed some light on what we mean by a "model that has been trained on data" in this article.
By now, you’ve probably seen the hype around neural networks. Just train them on your data and watch the sparkly results come out, right? Or even better — use a ready-made network, ask questions and get answers? Well, yes and no, it’s not that straightforward. In this article, we’ll look at how you can use neural networks to get answers from your data, without getting too caught up in the technical details. Although we’ll be looking at question answering specifically, most of the concepts we’ll cover translate over to other NLP-related tasks.
What Do All These Models Do?
Let’s talk about question answering models. Although there are different types of question answering models (extractive, generative and so on), as it’s a good starting point, here we base our explanations on extractive question answering. For a brief overview of the different types checkout this intro by Hugging Face.
You will frequently see question answering referred to as a search task, and there is a good reason for this. For the most part, a model trained for question answering is actually trained to search for the right answer. Question answering models don’t have the answers, they are trained to extract them from the data you provide them with. So, the models themselves do not contain any answers. Without data, the model has nothing to search through. And this here is the key concept that can be confusing.
When you hear about a model being trained on data, this “data” solely refers to the data that was used as a vehicle for that model to learn the task of finding answers in data. From that point on, they have learned clever ways to extract answers from data previously unseen to them! This data, in the world of question answering, is sometimes referred to as context (although heads up: context is used to mean other things too). The beauty of a machine learning model is that it will be able to read through this text much (much) faster than any human can.
A good way to demonstrate this "search and extract" behaviour of a question answering model is by having a look at QA models on Hugging Face* and trying some out. Let’s have a look at roberta-base-squad2, one of the most used general question answering models trained on a very generic dataset of all sorts of Wikipedia articles. Hugging Face has a feature that allows you to try out trained models at a small scale in the "Hosted inference API" section. Here, you’ll quickly notice that there are two input areas; one for a question, the other for context, which is the data the model will use to look for answers in. In this case, context can be a passage of text containing the answer:
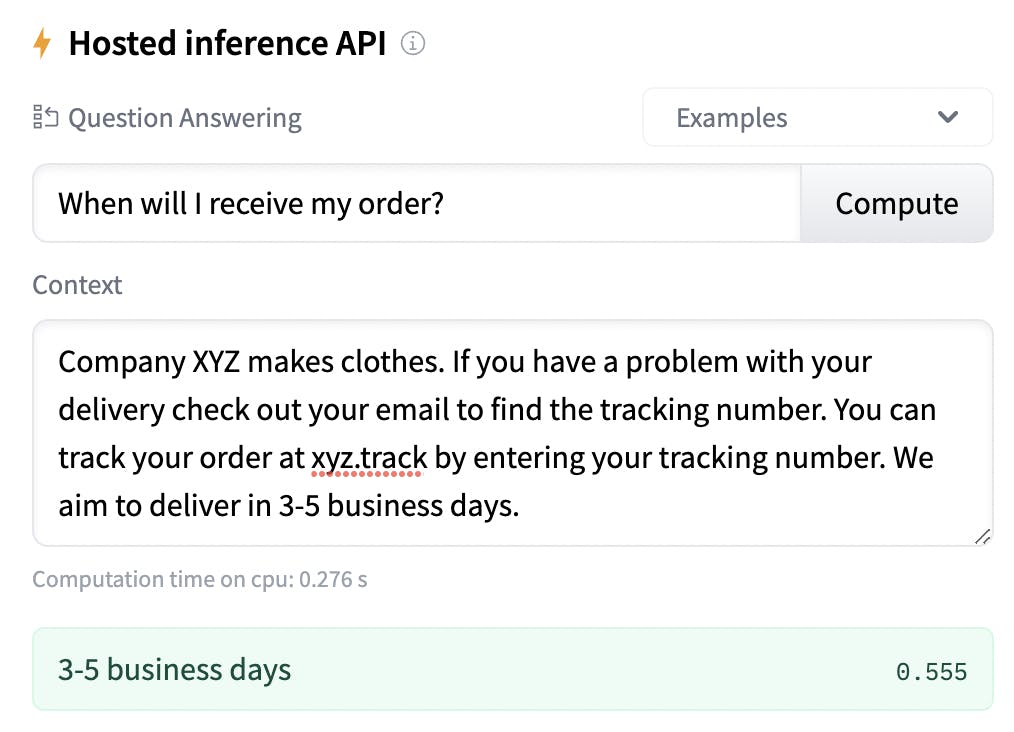
With the correct context (data), this general model is able to extract the right answer for me!
Now you should note that I am using the model as-is. I have not trained my own model on my own data. Why? The simple answer to that is “I don’t need to, because this general model works well enough!” And the good news is that this would hold true for a lot of other use cases too.
For many scenarios, you don’t need to train a model on your data because more than anything, training takes time and effort, which most of the time, is too costly to be worth it. If you’re lucky, a pre-trained, general-purpose model — maybe one that was trained on generic Wikipedia data like the one above — would be good enough to play around with your data. They’ve learned to do the thing they’re supposed to do: extracting answers for a given question, they just need you to provide the playing field (your data) to do that in. 😊
There are, of course, scenarios where a pre-trained model won’t be enough. E.g., a very domain-specific use case, such as biochemistry. These are situations where you might think of fine-tuning a model with your own data. But this is already a bit more advanced topic, so we can come back to it later.
* Hugging Face is a platform where you can upload and re-use machine learning models. It’s great, because it means that you can re-use models trained by others, and share your own with others too. If you’re familiar with GitHub, you can think of Hugging Face as the GitHub for trained models.
Note: There are actually various types of QA such as Extractive QA and Generative QA. For the purposes of this explanation, here we are talking about Extractive QA. For more information on the different types have a look at this intro by Hugging Face.
The Journey From Data to Model
Let’s imagine a real life scenario where you have a bunch of information and you want to enable searching through it via a question answering system. So really, you need some way to provide a (very) large amount of text data to a model. This stack of data is going to be where the model does its extracting answers to a question trick. Think of a scaled-up version you did in that context (data) box in the Hugging Face example above.
Here arise two problems: where to keep the data, and how to hand it to the model when a question is asked to it. This can end up being quite a complex and technically sophisticated journey. Because a) these models can be particular about the format of the piece of text they look at, and b) unfortunately, there’s a limit to how much data they can consume in one go. So this simple looking problem becomes an important one for a real-life, production scale use-case.
Luckily for us, developers have come up with solutions to this challenge and this is where you will see names like OpenSearch, Elasticsearch, FAISS, Weaviate come up. These are databases that store small pieces of text data that can be passed on to the model, one after the other. While it may appear simple to hand over individual small pieces of text to the model, one after the other, depending on the level of efficiency, accuracy and speed you’re after, it can become a bottleneck.
For example: It can take multiple hours to execute a single question on 10000 documents
Haystack
Haystack, our open source NLP framework, provides functionality for exactly this journey from data all the way up to answers to a question. In the next part of these series we will cover the journey from data to model in more depth. But here’s a sneak peak of what’s involved and how Haystack can help you in the process:
In terms of handling data that is to be used by a model, Haystack provides the capability to tell the model which relevant bits of text to even bother looking through. You can already imagine how much time that might save! As for the rest of the journey, you can define what model it is you want to use and so much more! Haystack is built on the idea of pipelines which you can think of as a combination of Lego blocks (which so-called nodes), where each block does one thing. For example, you can have a node that is able to retrieve only the relevant bits of text from your database based on a question. Another can be where you define which question answering model you want to use. We will get into more detail on this structure and how it provides a solution to the challenge of efficiently providing data to a model in the following article. But for those of you who are interested, let’s have a sneak peak:
By specifying one of the databases we mentioned above, e.g., Elasticsearch or OpenSearch, as the Haystack DocumentStore, you can make your data available in a Pipeline for question answering, for which Haystack already has a ready made pipeline.
Then, on top of that block you can continue to add more stuff like:
- A Retriever: That can take your DocumentStore and retrieve only the data that is relevant to the question you want to ask
- A Reader: That contains the QA model such as roberta-base-squad2 (the one we used above) that reads through the data and finds the answer
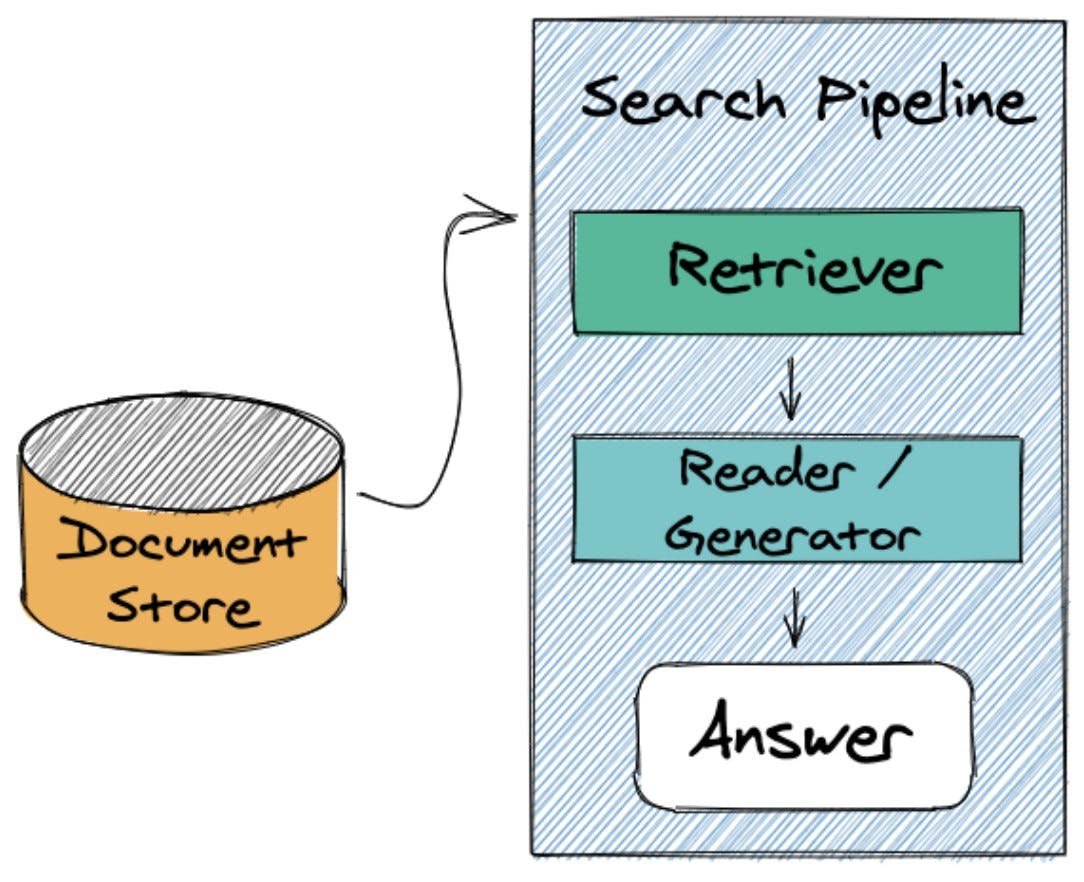
We will go into more detail about this structure and use case of Haystack Pipelines in the following chapter!
You can try out all of these steps in the Build Your First QA System Tutorial on Haystack.
Other Scenarios to Think About Data
This article is a simplified explanation of how question answering models work. There has been one big assumption: the domain we are in is general enough to work with a model like roberta-base-squad2. There are of course cases where such a general model won’t be good enough to yield results, e.g., question answering for biomedical data, where the language is very domain specific. These are scenarios where you may need “domain-adaptation”, where you fine-tune a model by essentially continuing to train it, but this time with your own, annotated data.
For more information on annotation and fine-tuning, check out our article on Labeling Data with Haystack Annotation Tool.
Last but not least, why not joining the Haystack community on GitHub and Discord right away 💙

