Picking the Right Haystack Reader Model
At the core of a question answering pipeline sits an intricate building block — the “Reader.” Let's zoom in on the inner workings of Haystack readers.
27.07.21

This article is the third in our series on optimizing your Haystack question answering system. We’ll link to the other articles here as they go online:
- Parameter-Tweaking
- Accelerate Your QA System with GPUs
- Picking The Right Reader Model
- Metadata Filtering
At the core of your Haystack question answering pipeline sits an intricate piece of machinery that we call “Reader.” It’s here that the actual question answering takes place. Equipped with a powerful deep language model, the reader processes batches of preselected documents to find the best answers to your natural-language queries.
In this blog post, we’ll zoom in on the inner workings of Haystack readers and provide some tips on how to pick the reader-language model combination best suited to your use case.
What Does the Reader Do?
Within the Haystack question answering (QA) pipeline, the reader object is your interface to a Transformer-based language model. This can be a publicly available model, your own trainable model, or a combination of both — where you fine-tune an existing model on your own dataset.
Language models parse both query and answer candidates, and return the most likely answer spans. Because of their ingenious Transformer architecture and the large amounts of data they see during training, they have a good understanding of the syntax and semantics of natural language. But they are also computationally expensive and much slower than the other components of the Haystack pipeline.
The reader also handles the details around making documents fit with the hardware. Thereby, we as the system users don’t have to worry about the internal representation of our queries — for all we know, we feed a natural language query to the model and it returns answer spans from our document collection, ranked by a matching score.
How to Use the Reader
Question: how easy is it to implement a QA pipeline in Haystack?
Answer: it’s a breeze!
Here are all the steps you need to follow to set up a fully functioning system:
- Set up a document store object and read in your documents.
- Choose a retriever and index your database with it.
- Choose a reader and a language model.
- Combine retriever and reader in a pipeline object.
To recap, the retriever preselects a handful of documents while the reader is responsible for extracting precise answer passages. For a refresher on how this looks in detail, have a look at our article on building a question answering system on top of an Elasticsearch database.
Let’s now get to the heart and soul of a QA pipeline and take a closer look at reader models.
Types of Reader Models
BART, BORT, or CamemBERT? The world of natural language processing is progressing fast, and new Transformer-based language models are being introduced on a regular basis. Haystack readers allow you to load any one of over 11,000 trained models from the Hugging Face Model Hub. You can do it by simply passing on the Model Hub's name to the reader object, like so:
reader = FARMReader(model_name_or_path=”deepset/roberta-base-squad2", …But how can we decide which model best fits our use case?
Fine-tuned models
Our first limitation comes from the fact that we actually require our model to be fine-tuned to the question answering task. In the Hugging Face’s Model Hub, we can filter for those models, which considerably narrows down our selection.
Fine-tuning, domain adaptation, and transfer learning are all different names for a common two-stage technique. First, a Transformer-based model — say, Facebook’s RoBERTa — is trained with huge amounts of language data. This way, the model acquires a solid general understanding of natural language. We then add a new layer on top of the model that performs a more specific task, like summarization, sentiment analysis, or question answering.
A specialized task requires specialized data. The dataset required for fine-tuning is commonly much smaller than what’s used to learn the language model. For extractive QA that allows for “None”-answers, the 150,000 question-strong SQuAD2.0 dataset is a popular choice. By fine-tuning our general-purpose RoBERTa language model to that dataset, we get RoBERTa_SQuAD (deepset/roberta-base-squad2): a model designed to extract the best answer passages for a query from large amounts of text.
Multilingual support
To further narrow down our selection, we have to know which language we want to work with. Of course, most NLP tasks perform best on English, the lingua franca of the Internet. But thankfully, more and more languages are getting attention.
We’ve recently announced the release of two datasets for question answering in German. Their Model Hub names are deepset/gelectra-base-germanquad and deepset/gelectra-large-germanquad.
The aforementioned CamemBERT (etalab-ia/camembert-base-squadFR-fquad-piaf) is a model for French, and there are now models for Italian, Spanish, Chinese, and other languages. Find more tips on working with different languages here.
The performance-speed tradeoff
While your choice of models is limited when it comes to most languages, the reverse is true for English: there are many different language models and it can be hard to know which to pick. To help you with that decision, you should always ask yourself two questions:
- How fast do I need my model to be?
- How much computational power do I have?
Usually, these two requirements influence one another. For instance, while most language models are so big that they require at least one GPU to run, there are lightweight models like MiniLM (deepset/minilm-uncased-squad2) that will work on just the CPU of your laptop. However, working with this model will likely require a tradeoff in terms of performance. On the other hand, a SOTA model like the large ALBERT XXL (ahotrod/albert_xxlargev1_squad2_512) will show excellent results, but at the expense of being slower.
Benchmarks: quantify and compare performance between models
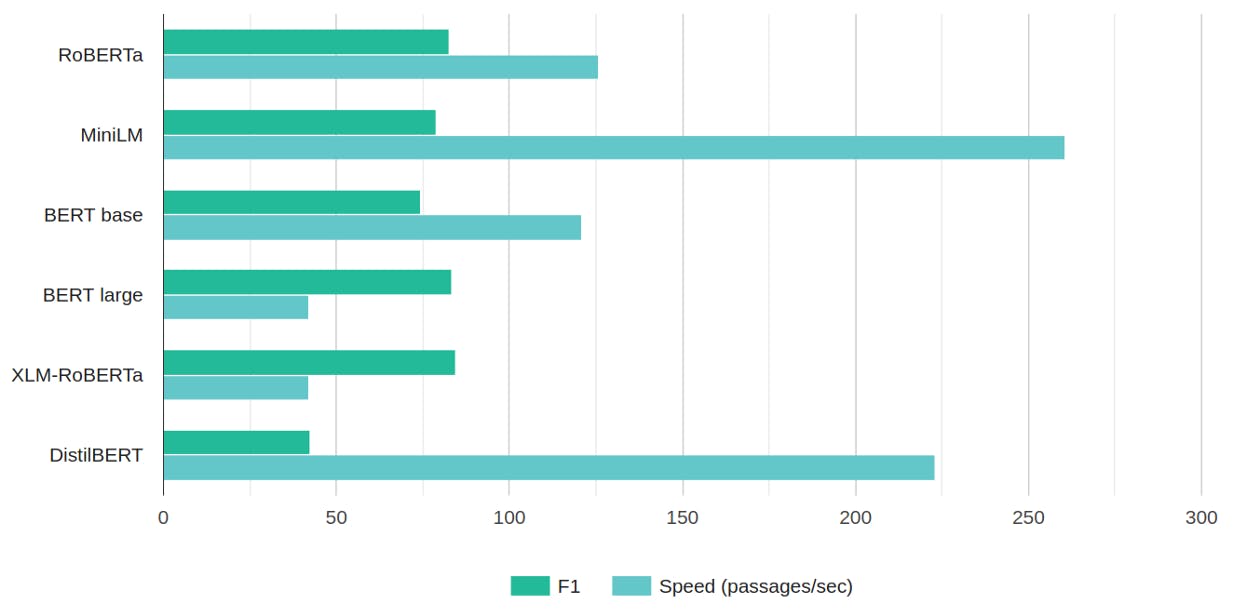
When it comes to the advantages of one model over another, you can take our word for it — or you could check out the benchmarks we’ve posted here. The above plot compares speed and accuracy (the F1 score, a weighted metric of precision and recall). A quick glance tells you why we recommend using RoBERTa for most tasks: it performs as well as the large BERT model — but does so in a third of the time.
RoBERTa has the same number of parameters as BERT, but it was trained on ten times the amount of data. This means that while training RoBERTa is slower and computationally more expensive, during inference it doesn’t take longer than BERT. Hugging Face currently lists 60 RoBERTa models fine-tuned on different question answering tasks, among them models for Chinese and Arabic. There’s even a model fine-tuned on questions related to COVID‑19!
Types of Reader Implementations
You may choose between two classes of readers in Haystack. There’s TransformersReader (part of Hugging Face’s Transformers library for NLP) or our own FARMReader. Unless you’re an experienced user of the Transformers QA pipeline, we’d strongly advise you to go with the FARMReader.
Advantages of FARM over Transformers
The acronym FARM stands for “Framework for Adapting Representation Models.” Like the Haystack library, the framework was developed by deepset. Its purpose is to allow for transfer learning, that is, the adaptation of deep learning models to specific use cases in industrial settings. FARMReader is built on top of FARM’s models and classes.
As a model native to the framework, FARMReader is regularly updated for usability and optimized for performance by its Haystack maintainers. As we mentioned earlier, you can also fine-tune an existing model with your own labeled data within Haystack — if that sounds interesting, check out the Haystack annotation tool, which helps you create your own dataset! TransformerReader can also be fine-tuned, but only within the Transformers library.
Unlike TransformersReader, FARMReader removes duplicate answers automatically, so that no answer from the same slice of text shows up twice during inference. In addition, both the selection of answer spans and their ranking are done a bit differently (and, to our mind, more intuitively) than in the Transformers library — have a look here if you’re interested in the details).
How to Initialize a Haystack Reader Model
Let’s now look at a practical example of using a reader in Haystack, taking note of important parameters we can set when initializing the reader object with a language model:
my_model = "deepset/roberta-base-squad2"
reader = FARMReader(model_name_or_path=my_model, use_gpu=True, return_no_answer=True, no_ans_boost=0, top_k=5)We set use_gpu to “True” to provide enough computational power for our model to run. We also set return_no_answer to “True.” This is important if you want to avoid receiving low-confidence answers. If the confidence values for your answers fall under a certain threshold, your model will return “None” answers. That threshold can be raised by passing a positive value to the no_ans_boost parameter.
Finally, we specified that we want our model to return the five best answers by setting top_k=5. Alternatively, we can set this parameter when we run our pipeline:
pipeline = ExtractiveQAPipeline(reader, retriever)
pipeline.run(query=query, top_k_retriever=10, top_k_reader=5)Here, the same parameter is called top_k_reader, as distinguished from top_k_retriever. Unlike top_k_reader, your choice of top_k_retriever greatly impacts your system’s speed. To learn more about parameter tweaking, take a look at our article on the topic.
Start Building Your Own Haystack Pipelines
It’s time to fire up your own Reader-Retriever pipeline and apply the combined power of Transformers and large question answering datasets to your use case.
If you have access to GPUs, the combination of FARMReader + RoBERTa language model will be the right choice in most scenarios.
Visit our GitHub repository and get started with Haystack. We would greatly appreciate you giving us a star too :)

